Data is being generated at an unprecedented rate of 2.5 quintillion bytes per day, making it a valuable asset for businesses. However, interpreting and understanding this vast amount of information is challenging. This is where data science comes to the rescue with its powerful tools and techniques to extract valuable insights from the information. But this is not a one-person job; it’s a collaborative effort involving a team of professionals with different expertise.
Data engineer roles and responsibilities cover developing and managing the end-to-end infrastructure. They create processing algorithms and construct systems capable of managing large amounts of data. According to the 2020 Dice Tech Job Report, data engineering is the fastest-growing position in the tech industry, with a 42.2 percent year-over-year growth in open positions (as of the 2022 version of this report).
In this article, we will explore the roles and responsibilities of data engineers and discuss the educational and professional background needed to pursue a career in this field.
Table of Contents
What Does a Data Engineer Do?
Data engineers play a vital role in the process of data analysis by ensuring that information is collected, stored, and made accessible to the right people at the right time. Their primary responsibility is to construct and maintain the infrastructure that enables organizations to extract valuable insights from their information.
This type of work also includes creating and managing storage systems, designing processing pipelines, and developing algorithms to analyze large datasets. These specialists also act as the backbone of any data-driven organization, bridging the gap between raw details and actionable insights to facilitate informed decision-making.
How Do Data Engineers Bring Value to Organizations?
Data engineer roles and responsibilities cover designing, developing, and maintaining the pipelines that enable organizations to collect, store, process, and deliver information to different stakeholders. Let’s look at how they are valuable:
- Data Pipeline Construction. Engineers are critical in efficiently managing information by designing and constructing pipelines that allow seamless data transfer from various sources to warehouses or lakes. These pipelines are essential to organizations as they provide a consolidated and dependable information source, enabling them to make informed and data-driven decisions on time.
- Data Quality Assurance. They utilize various cleaning and validation techniques to ensure that the analysts have accurate and consistent information to work with. One of the biggest challenges data analysts face is identifying and correcting errors or inconsistencies in information.
- Scalability. Data engineers are highly skilled professionals specializing in designing and implementing complex systems that can handle massive amounts of information. They are crucial in ensuring an organization’s infrastructure is robust, scalable, and efficient, accommodating exponential volume, velocity, and variety growth.
- Algorithmic Bias Mitigation. Algorithmic biases can have serious implications. To mitigate such biases, engineers play a crucial role in ensuring that pipelines are designed fairly and transparently.
- ETL (Extract, Transform, Load) Processes. The process of converting unstructured or semi-structured information into a structured format is commonly referred to as ETL operations. These operations are of the utmost importance as they play a critical role in enabling scientists and analysts to access transformed information that is ready for analysis. By structuring the information properly, analysts can unlock valuable insights and make informed decisions based on the information.
- Data Security. Engineers play a critical role in maintaining the security of sensitive information. They implement a comprehensive set of measures to safeguard against unauthorized access, theft, or misuse of valuable information. These measures are designed to meet evolving and complex privacy regulations and are essential for maintaining trust and compliance with industry standards.
The Role of a Data Engineer
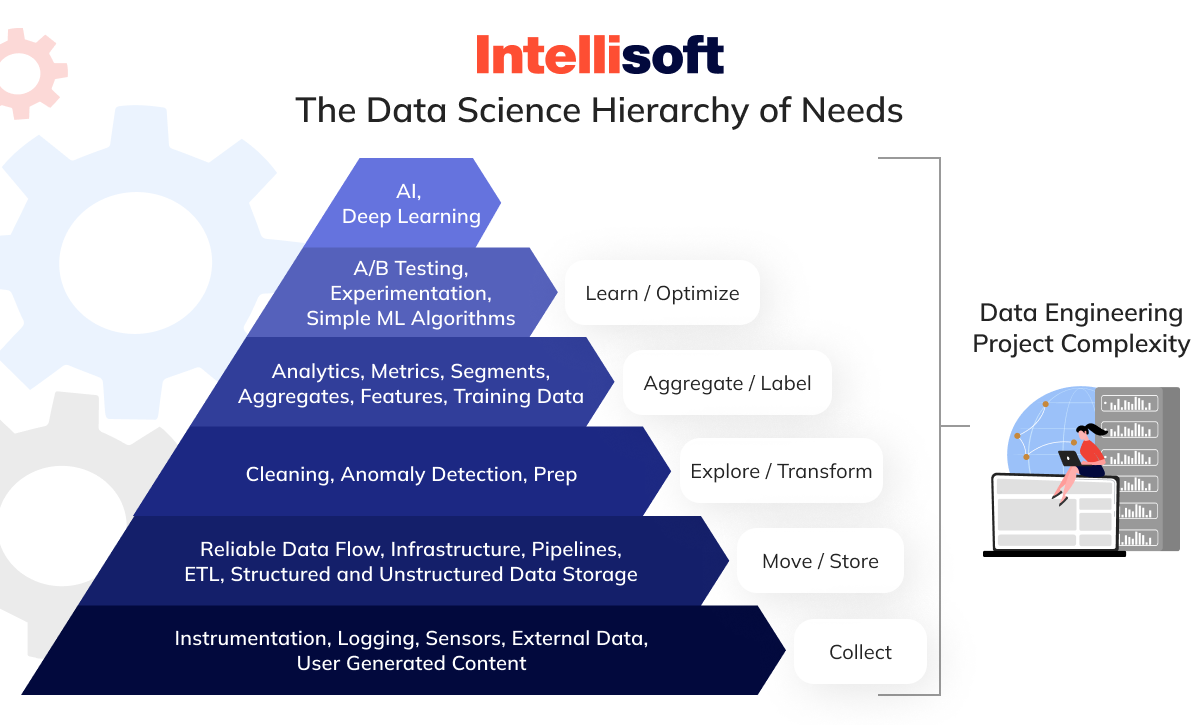
Big data engineer roles and responsibilities are adaptable based on the project’s requirements. Its complexity will depend on the overall complexity of the data infrastructure. Let’s take a closer look at the Data Science Hierarchy of Needs. We can observe that when more sophisticated technologies such as machine learning or artificial intelligence are implemented, the pipelines become increasingly intricate and require more resources.
To better understand the concept of infrastructure, let’s first discuss the three essential stages that information undergoes before it is presented to business users as readable reports or dashboards. Then, we can discuss the tools used to manage information.
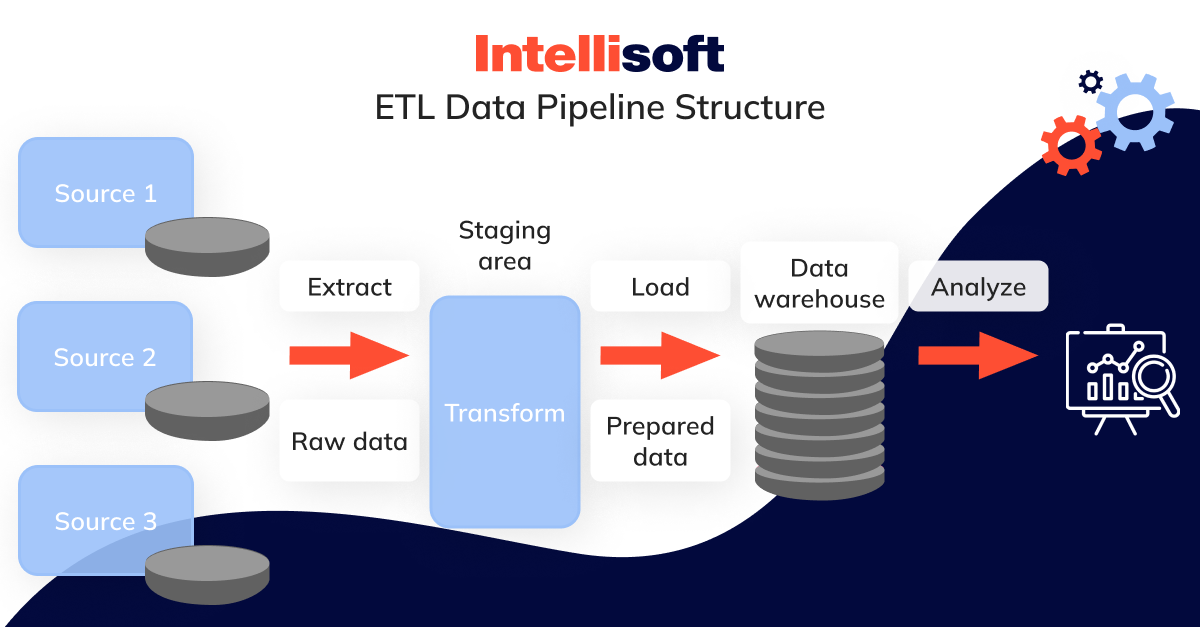
- Extracting data. Our surroundings are teeming with information. However, the real challenge lies in harnessing this information from its diverse sources and leveraging it effectively. In the business world, it often translates to accessing corporate information stored in databases or internal ERP/CRM systems. Sometimes, information may originate from many IoT sensors scattered across a manufacturing facility or an aircraft, and valuable insights can often be gleaned from online public sources.
- Transformation. The analysis process encompasses two pivotal stages; the initial analysis stage and the transformation stage. The initial analysis stage is dedicated to comprehending the information in its raw form, while the transformation stage enhances, organizes, and formats data sets to render them suitable for analysis and reporting.
- Loading and storage. When we gather insights for analytical purposes, we have to store it somewhere. A common way to store information is using a data warehouse. However, in some cases, more complex pipelines may require the use of other types of repositories, such as lakes, lakehouses, marts, and similar storage solutions.
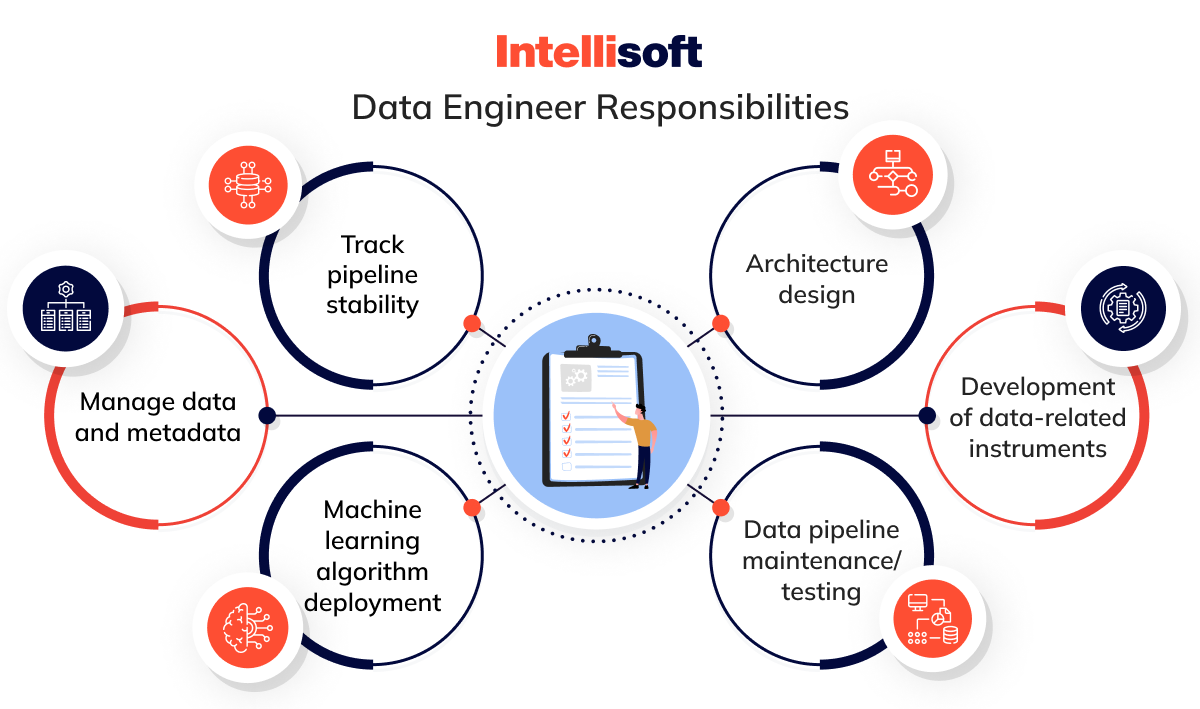
Architecture design
Data engineering is a vital field that involves the intricate process of designing the underlying framework of a data platform. In some larger enterprises with more complex processes, a data architect who specializes in designing the overall architecture of the platform may have a dedicated role.
Development of data-related instruments
The role of a big data engineer primarily revolves around development and programming skills. These experts use their technical prowess to create, customize, and maintain various integration tools, databases, warehouses, and analytical systems.
Data pipeline maintenance/testing
In the crucial development phase, engineers play a pivotal role. They meticulously test the reliability and performance of each system component, or they can collaborate with the testing team, underscoring their integral contribution to the process.
Machine learning algorithm deployment
Data scientists are responsible for creating machine learning models, while engineers are responsible for deploying them to production environments. Tasks involved in deployment include providing access to information, configuring information attributes, managing computing resources, setting up monitoring tools, and more. ML engineers may also be involved in this process.
Manage data and metadata
Data repositories are designed to store information in structured or unstructured form. However, in addition to the actual information, metadata needs to be managed. This is where engineers come in. They manage various information types, including metadata, mainly when no dedicated metadata manager exists.
Track pipeline stability
It is crucial to monitor the system’s performance and stability to ensure that everything is running smoothly. Just as a warehouse needs to be cleaned periodically, the system needs to be monitored regularly. It is also necessary to monitor and modify the automated parts of the pipeline to accommodate changes in information, models, or requirements.
Data Engineer Skills and Toolset
The necessary skills are directly linked to the specific roles and responsibilities of data engineer. The specific skill set required for a data engineer can vary widely depending on the project and organization they are working for, as engineers may be involved in a broad range of tasks. Typically, an engineer’s activities cover three primary areas: engineering, database and warehouse management, and data science.

Engineering skills
To pursue a successful career in data engineering, it is essential to have a strong background in software engineering. A big data engineer should be proficient in one or multiple programming languages as most analytical tools and systems are written in Java (such as Hadoop and Apache Hive) and Scala (such as Kafka and Apache Spark).
On the other hand, Python has gained immense popularity and is now considered the most widely used language for machine learning projects, so engineers often master it first. High-performance languages such as C/C# and Golang are also quite popular among engineers, especially in training and implementing machine learning models.
Database/warehouse knowledge
Data engineers are essential to effectively managing diverse types of storage. To perform their role effectively, they require a strong grasp of SQL and NoSQL databases and a comprehensive understanding of database management systems such as MySQL, Oracle, PostgreSQL, MongoDB, and others. This knowledge enables them to handle information efficiently, ensuring that it is correctly stored, managed, and maintained.
Data warehouse plays a pivotal role in storing, organizing, and managing the massive amounts of data businesses generate. As a result, specialists must be well-versed in modern cloud-based warehouse technologies such as BigQuery, Snowflake, Firebolt, and Amazon Redshift. This knowledge enables them to choose the most appropriate warehouse architecture, set it up, and maintain it effectively.
Doing so ensures that the information remains easily accessible and secure while also being meticulously organized. As a result, their work has a significant impact on the organization’s success, as well as its ability to make informed business decisions.
Data-related expertise
Data engineers play a critical role in data science, working closely with scientists to create and maintain the necessary infrastructures to process and analyze information effectively. They must possess in-depth knowledge of information modeling, algorithms, and transformation techniques to develop ETL/ELT pipelines, storage, and analytical tools. Hands-on experience with existing ETL and BI solutions is crucial to ensure the smooth functioning of these tools.
In addition, data engineers who work on projects that use specialized instruments such as Kafka or Hadoop require specific expertise. They must have comprehensive knowledge and experience with these instruments to handle such projects effectively. If the project is associated with machine learning and artificial intelligence, engineers must have experience with ML libraries and frameworks to provide the necessary support. Data engineers play a vital role in the data science ecosystem and must possess a diverse skill set to succeed in this field.
In summary, engineer’s expertise involves:
- A complete understanding of data science concepts
- Expertise in data analysis
- Relevant experience with ETL/ELT tools (for example, IBM DataStage Informatica Power Center, Oracle Data Integrator, Talend Open Studio)
- Knowledge of BI tools (Tableau, Microsoft Power BI)
- Big data technologies (for example, Hadoop and Kafka).
- Knowledge of ML frameworks and libraries to work on projects related to ML and AI (TensorFlow, Spark, PyTorch, mlpack)
Soft skills
Every tech role requires a specific set of skills to ensure optimal performance. Data engineering is no exception. In addition to technical knowledge, engineers must possess several soft skills to excel in their work.
Creativity and problem-solving are among a data engineer’s most essential soft skills. These skills are crucial for finding optimal and often innovative solutions to complex issues, which are a big part of an engineer’s daily work.
Attention to detail is not just a skill, but a superpower for data engineers. It enables them to carry out monotonous tasks with precision and accuracy, ensuring the quality and reliability of their work. Moreover, the ability to break down large problems into smaller, achievable steps is a critical skill that such specialists must possess, further underlining the importance of meticulousness in data engineering.
Lastly, the ability to communicate effectively is not just a bonus but a necessity for an engineer. Seamless collaboration with team members and other stakeholders is a cornerstone of project success. Hence, these experts must be adept at articulating their ideas and solutions clearly and concisely.
Related articles:
- Solution Architect: Role Description, Responsibilities, and Processes
- Lead Your Projects to Success with a Solid Project Team Structure
- Things to Know About Data Processing Agreement (DPA)
- Vendor Management IT. Definition, Features, Advantages, and More
- Who Does What? Understanding Roles in a Software Development Startup
When to Hire a Data Engineer?
As a business owner, you know that data can be a powerful tool that can help you make informed decisions and drive growth. However, creating a data-driven culture can be daunting, requiring specialized knowledge and skillsets. There are some scenarios when you might need a data engineer.

Scaling your data science team
If your company has a team of specialists responsible for managing its technical infrastructure, it should have the right people to develop and maintain it. When your team lacks the necessary technical expertise, an engineer could be an excellent choice as a general specialist.
Running big data projects
Data engineering increasingly focuses on projects that involve processing and managing large amounts of information and creating complex integration pipelines. To accomplish these tasks, it is typically best to assemble a dedicated team of engineers responsible for specific infrastructure components.
Requiring custom data flows
Processing, analyzing, and managing large amounts of information can be complex and challenging, especially for medium-sized companies. Custom engineering is the solution in such cases. Automated business intelligence platforms rely on the primary principles of ETL (Extract, Transform, Load). However, companies may use different storage and processes for multiple information formats in practice, requiring a large technological infrastructure that can only be built and managed by a versatile specialist. A data engineer is the most suitable role for this case.
Data Engineer Job Requirements
A blend of educational qualifications and hands-on technical skills is essential. Here’s a breakdown of what candidates generally need:
- A relevant higher-education degree (computer science, engineering, or information technology)
- Proficiency in programming languages (Python, Java, or Scala)
- Experience with Hadoop, Spark, Kafka, or similar big data technologies
- Knowledge of relational (e.g., SQL, PostgreSQL) and non-relational (e.g., MongoDB, Cassandra) database management systems
- Familiarity with integration and ETL tools (Talend, Informatica, Apache NiFi, and others)
- Solid problem-solving and analytical skills
- Outstanding communication and collaboration abilities
What to include in the Data Engineer Job Description?
In this segment, we will discuss the vital components that should be included in every job description section for this position.
Description
This section introduces the job position and aims to provide potential candidates with a clear understanding of the role and its requirements. This section gives a brief overview of the company, its mission statement, and why it seeks to fill this position. Additionally, give an overview of the kinds of tasks and projects that the successful candidate will handle.
Moreover, you should list the technical requirements for the job, including technical skills, programming languages, and software experience. Finally, mention the level of experience your company seeks to help job seekers decide if they are suitable candidates and if it’s worth investing their time and energy in submitting a formal application.
Data Engineer Responsibilities
A data engineer is a highly specialized professional with in-depth knowledge and expertise in data science, software development, and database management.
As this role can vary depending on the job’s specific requirements, there are certain essential responsibilities that every engineer should be proficient in.
- Architecture design. These specialists are often responsible for designing a company’s data architecture. They need to be knowledgeable about various databases, warehouses, and analytical systems (for example, you can write about Snowflake data engineer roles and responsibilities).
- ETL processes. Engineers collect, process, and store information in a ready-to-use format in the company’s warehouse.
- Data pipeline management. Pipelines are crucial for engineers. Their ultimate goal is to automate information processes; pipelines are key to achieving this. Data engineers must be skilled in developing, maintaining, testing, and optimizing pipelines.
- Machine learning model deployment. While data scientists develop machine learning models, data engineers put them into production.
- Cloud management. More companies are turning to cloud-based services to manage their infrastructure. As a result, data engineers need to be proficient in working with cloud tools from providers like AWS, Azure, and Google Cloud.
- Data monitoring. Information quality is essential for the smooth operation of all processes. Data engineers monitor all processes and routines and optimize their performance.
Experience
The role of a data engineer is a fairly recent addition to the field of data science. Due to its novelty, only a few universities and colleges offer specialized degrees in this field. Engineers typically come from diverse backgrounds, such as data science, software engineering, mathematics, or even business-related fields.
However, to broaden the pool of applicants, consider candidates with significant relevant work experience despite not having a formal degree in data engineering. This approach could help assess applicants’ competencies holistically and lead to a more diverse and effective team.
Minimum Qualifications
Due to their role’s highly technical nature, engineers must be proficient in a wide range of tools. However, creating a comprehensive and detailed list of tools and technologies needed to succeed in any engineering position can be challenging. The data science ecosystem constantly evolves, with new technologies and systems emerging constantly.
As a result, it is advisable only to include the software, technologies, and tools necessary for the job or planning to adopt in the future. When creating a data engineer job description, you should frame the qualifications specifically for engineers and avoid listing general skills. To achieve this, consult the team members working with the selected candidate.
Aside from having the necessary technical expertise, possessing the proper set of soft skills is equally essential for the job. To ensure a comprehensive job description, companies should include the following qualifications and skills:
- Advanced SQL capabilities and knowledge of relational database management
- Proficiency in Python, Java, Scala, and other object-oriented languages
- Experience with distributed computing frameworks, such as Hadoop or Spark
- Familiarity with data pipelines and workflow management tools, such as Airflow
- Competence with cloud-based platforms, including AWS, Azure, and Google Cloud
- Strong project management and organizational abilities
- Exceptional problem-solving, communication, and organizational skills
- Demonstrated ability to work both independently and collaboratively with a team
Data Engineer Job Description Template
Here is a template for a job description you can customize to fit your team’s hiring requirements.
Description
Our company is expanding its team of analytics experts and is currently seeking an experienced data engineer. In this crucial role, you will develop, maintain, and optimize our warehouse, pipeline, and products. You will support multiple stakeholders, including software developers, database architects, data analysts, and scientists, in ensuring an optimal delivery architecture.
We are looking for an outstanding candidate with excellent technical skills and the ability to tackle complex problems. The ideal candidate should have a passion for learning new technologies and tools and be comfortable providing support to multiple teams, stakeholders, and products. The role requires someone who is highly adaptable, able to quickly understand and respond to the organization’s information needs, and able to work collaboratively with others.
[Add a detailed description of project types and information sources and specify expected deliverables.]
Responsibilities
- Design, construct, and manage both batch and real-time pipelines in a live environment.
- Oversee and enhance the data architecture necessary for precise information extraction, transformation, and loading from a diverse range of sources.
- Develop ETL (extract, transform, load) processes to facilitate the extraction and manipulation of information across various systems.
- Streamline data workflows including ingestion, aggregation, and ETL tasks.
- Prepare raw datasets in Data Warehouses for use by both technical and non-technical stakeholders.
- Collaborate with data scientists and leaders in sales, marketing, and product teams to implement machine learning models in production environments.
- Develop, oversee, and implement data products for analytics and data science groups using cloud platforms such as AWS, Azure, and GCP.
- Maintain information precision, integrity, privacy, security, and compliance through rigorous quality control measures.
- Monitor the performance of systems and apply optimization techniques.
- Implement information controls to ensure privacy, security, compliance, and quality across designated areas of responsibility.
[If necessary, add additional job requirements]
Experience
Bachelor’s degree in Computer Science, Information Systems, or a related field.
[X+ years of working experience.]
Minimum Qualifications
- Proficiency in advanced SQL and experience with relational database management and design.
- Knowledge and experience in cloud-based Data Warehouse technologies such as Snowflake, Redshift, BigQuery, and Azure.
- Experience with ingestion technologies including Fivetran, Stitch, and Matillion.
- Knowledge of cloud solutions including AWS, Azure, and GCP.
- Experience in creating and deploying machine learning models in a live environment.
- Strong skills in object-oriented programming languages such as Python, Java, C++, and Scala.
- Proficiency in scripting languages, specifically Bash.
- Expertise in managing pipelines and workflow tools like Airflow and Azkaban.
- Excellent project management and organizational abilities.
- Superior problem-solving, communication, and organizational skills.
- Demonstrated capability to work both independently and as part of a team.
[Ensure that you mention any relevant technologies.]
What will make you stand out
- Proficiency with NoSQL databases such as Redis, Cassandra, MongoDB, or Neo4j.
- Familiarity with handling large information sets and distributed computing technologies like Hive, Hadoop, Spark, Presto, or MapReduce.
[If necessary, add a preferred qualification]
The provided template can be a strong foundation for creating job descriptions. However, you can customize and tailor it to suit your specific needs. For instance, if you’re hiring a specialist for a senior-level role, you can augment the template by including additional senior data engineer roles and responsibilities, such as team management, data integration, and report generation.
Alternatively, if you’re looking to hire a prominent engineer, you can modify the template to focus on the tools and systems with which the candidate will work. In this case, you can highlight the importance of having a good understanding of frameworks like Hadoop and Spark and familiarity with tools such as Mesos, AWS, and Docker.
Extra Tips for Writing a Compelling Data Engineer Job Description
It’s not enough to just create a great job description and set expectations for potential candidates. With the overwhelming number of job ads out there, it’s easy for your ad to get lost in the shuffle. To make sure your job descriptions stand out and attract the right candidates, you should make them engaging and eye-catching. Here are some tips to help you achieve this goal:

- Include the salary range. By providing a salary range that matches the requirements and seniority for a data engineer position, you can attract the right candidates to your job opening. For example, the salary range should match lead data engineer roles and responsibilities, if you’re looking for such a specialist.
- Include benefits. In recent years, job seekers have become more discerning, emphasizing labor conditions and work-life balance. Therefore, employers must highlight these aspects in their job openings to make them more attractive and stand out.
- Provide insight into workplace culture. When seeking potential candidates for employment, it’s always helpful to provide detailed information about the team, culture, and values of the workplace. Doing so gives candidates a better idea of what it would be like to work with you and help them determine whether they would be a good fit for your organization’s culture.
- Define the hiring process with human resources. Job applicants are often curious to learn about the various stages of the recruitment process, such as interviews and meetings, to prepare and present themselves in the best possible manner.
Conclusion
If your organization is looking to leverage the power of data engineering, consider partnering with IntelliSoft. We maintain a wide pool of talented professionals that have deep technical knowledge and stay up-to-date with the latest tools and technologies. This approach allows us to quickly assemble the right team for your project and minimize the time and effort required for hiring.
Outsourcing your data engineering needs to IntelliSoft can be more cost-effective than maintaining an in-house team, particularly for projects with fluctuating resource requirements or specialized skill sets. Our flexible engagement models allow you to scale your data engineering resources up or down as your project demands, providing agility and adaptability to changing business needs.
By entrusting your data engineering responsibilities to our team, your organization can concentrate on its core strengths and strategic initiatives while we handle the complex task of infrastructure management.
Don’t let data engineering challenges hold your organization back. Contact IntelliSoft today to explore how our data engineering services can empower your business with actionable insights and drive growth.