Need Help With Kafka Integration?
Imagine orchestrating a symphony of conversations in a bustling city square, where thousands of users exchange information, share news, and react to events. In this dynamic environment, a reliable and efficient messaging system is the invisible conductor, ensuring every message reaches its intended recipient without delay or disruption. Similarly, modern software applications require robust messaging systems to handle the complex communication between their many components.
RabbitMQ and Apache Kafka are leading messaging systems facilitating vital data exchange and events in the software development industry. They play a crucial role in developing scalable and efficient applications by enabling seamless communication between various software components and helping manage complex data workflows. But how do you decide which “conductor” suits your application’s symphony?
Our team has extensive experience integrating messaging systems into complex application architectures, such as the ZyLAB project. This article will explore the differences between Kafka vs RabbitMQ, their architectures, use cases, and strengths and weaknesses. We’ll also provide guidance on Kafka vs RabbitMQ messaging systems to choose from based on your application’s requirements.
Table of Contents
Explaining the Concepts of a Publish/Subscribe (Pub/Sub) Messaging System and a Message Broker
Before delving into the specifics of RabbitMQ and Kafka, it’s essential to understand the fundamental differences between a publish/subscribe (pub/sub) messaging system and a message broker.
Definition of a Message Broker
A message broker is an intermediary between various application components, facilitating communication by transferring data. The primary function of a message broker is to route information from producers (message senders) to consumers (message receivers) based on predefined rules and logic. By employing a message broker, applications can focus on their core functionalities while the broker handles message delivery and routing.
Definition of a Pub/Sub Messaging System
On the other hand, a publish/subscribe messaging system is a messaging pattern where producers (publishers) send messages without specifying recipients. Instead, they categorize messages into topics or channels. Then, consumers (subscribers) express interest in particular issues and receive notifications that match their subscriptions. This messaging pattern allows for decoupling between producers and consumers, enabling greater flexibility and scalability in application architecture.
Comparing Message Brokers and Pub/Sub Messaging Systems
Both message brokers and pub/sub messaging systems are vital in facilitating communication between application components. However, they differ in how they route messages and handle producer-consumer relationships.
A message broker focuses on routing messages based on predefined rules, ensuring that information reaches the appropriate consumers. It may support various messaging patterns, such as:
- Request/Reply
- Point-to-Point
- Pub/Sub
On the other hand, a “pub/sub” messaging system emphasizes the decoupling of producers and consumers. It allows multiple consumers to receive messages from a single producer by subscribing to the same topic or channel.
Message brokers provide reliable information delivery and ensure messages reach the intended recipients. They can also offer message persistence, transformation, and routing options. However, they may introduce a single point of failure and can become a performance bottleneck if not adequately managed.
Pub/sub messaging systems enable greater flexibility and scalability, allowing applications to evolve without impacting the communication between producers and consumers. However, they may not provide guaranteed message delivery or advanced routing features.
Now that we’ve covered the differences between message brokers and pub/sub-messaging systems, let’s explore RabbitMQ and Kafka in more detail.
What Is Kafka?
What is Apache Kafka? It is a streaming platform with a distributed architecture designed for high-throughput, fault-tolerant, and scalable data streaming applications. It was initially developed at LinkedIn and later open-sourced in 2011. Numerous organizations widely adopt Kafka for building real-time data pipelines, streaming applications, and event-driven architectures.
Origin and History of Kafka
Jay Kreps, Neha Narkhede, and Jun Rao have created Kafka to address the growing need for a high-performance, distributed messaging system to handle the vast amounts of data generated by LinkedIn’s infrastructure. Traditional messaging methods couldn’t manage real-time data feeds effectively, so they started the Kafka project to provide a unified, high-throughput, low-latency platform.
Kafka Architecture
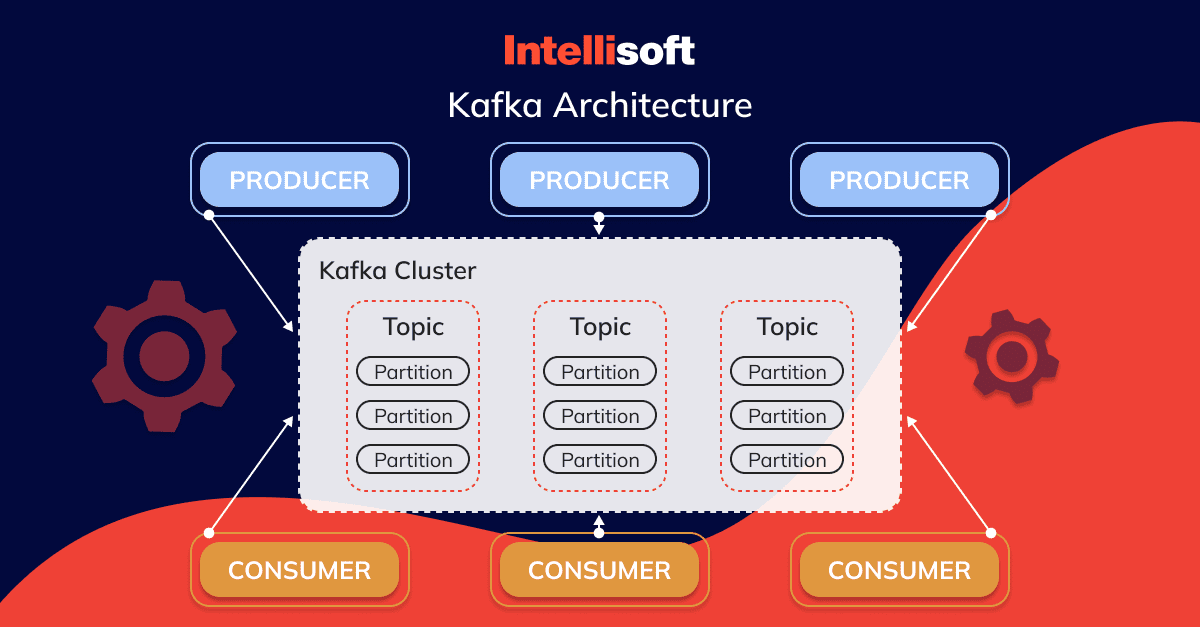
Developers have built Kafka’s architecture around a distributed and replicated commit log service, which is the core of its messaging functionality. Fundamental components of Kafka’s architecture include:
- Producers: Entities that send messages to Kafka.
- Brokers: These are Kafka nodes that store and manage published messages.
- Topics: Categories or channels to which producers publish messages.
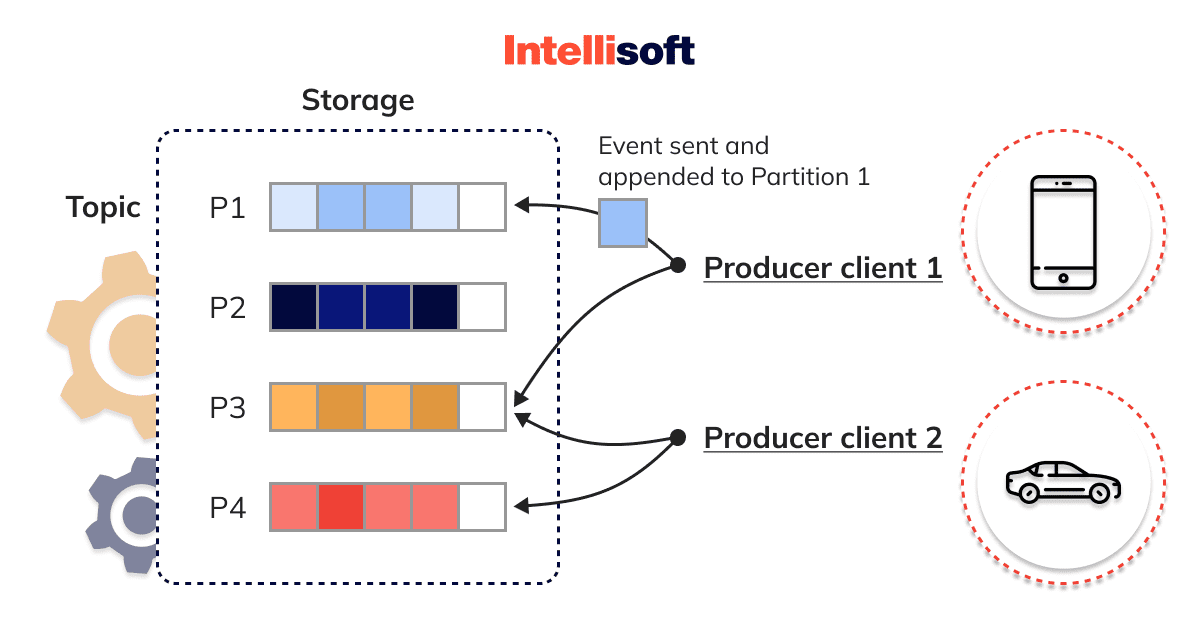
- Partitions: Kafka divides topics into multiple, ordered, and immutable sequences of records known as partitions, enabling parallelism and increased throughput.
- Consumers: Entities that read and process messages from Kafka.
- Clusters: Collections of Kafka brokers working together to manage and distribute data across multiple nodes.
- Consumer Groups: Sets of consumers in Kafka that collaborate to consume data from one or more topics.
- Replicas: Copies of a Kafka partition distributed across multiple brokers.
- Leaders: Designated brokers within a Kafka cluster responsible for handling all read and write requests for a specific partition.
- Followers: Brokers in a Kafka cluster that passively replicate the leader’s data for a given partition, ready to step in as the new leader if the current leader fails.
Kafka provides strong durability guarantees, as messages are persisted on disk and replicated across multiple brokers. This approach ensures high fault tolerance and minimal data loss in case of node failures.
What Is RabbitMQ?
RabbitMQ is an open-source message broker implementing the Advanced Message Queuing Protocol (AMQP). It was first released in 2007 and has since gained widespread adoption for its flexibility, reliability, and ease of use. By operating as a message broker and queueing server, RabbitMQ enables diverse applications to exchange data through a standard protocol or queue tasks for processing by distributed consumers. RabbitMQ queues can store tasks, allowing the broker to manage load balancing and task distribution.
Origin and History of RabbitMQ
Rabbit Technologies Ltd, a company founded by Alexis Richardson and Matthias Radestock, has developed RabbitMQ to create a high-performance, scalable, and easy-to-use message broker that supports a variety of messaging patterns and integrates with various platforms and languages.
RabbitMQ Architecture
RabbitMQ’s architecture consists of several key components that facilitate message delivery and routing:
- Producers: Entities that send messages to RabbitMQ.
- Exchanges: These components are responsible for receiving messages from producers and routing them to the appropriate queues based on predefined rules.
- Queues: Buffers that store messages until consumers consume them.
- Bindings: Rules that define the relationship between exchanges and queues, determining the routing of the messages.
- Consumers: Entities that receive and process messages from RabbitMQ.
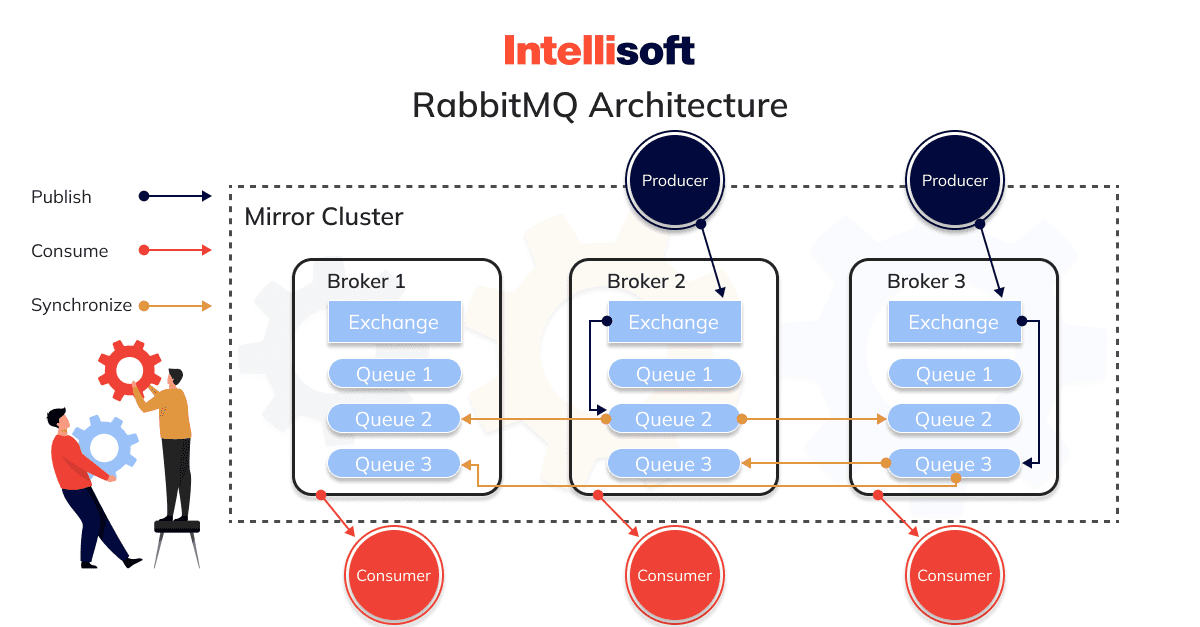
RabbitMQ is known for its flexible routing capabilities, ease of use, and support for multiple messaging protocols, including AMQP, MQTT, and STOMP.
What Is Kafka Used For?
Kafka has a variety of use cases, making it a popular choice for different types of applications. Some common Kafka use cases include:
- Data Streaming
- Real-Time Analytics
- Distributed Systems
Kafka in Data Streaming and Real-Time Analytics
Data streaming is one of Kafka’s primary use cases where it acts as a highly scalable and fault-tolerant messaging system that enables real-time data processing. Kafka’s ability to handle high-throughput data streams makes it ideal for real-time ingesting and processing large data volumes. Because of this feature, Kafka is well-suited for log aggregation, real-time analytics, and data warehousing applications.
Kafka in Distributed Systems
You can also employ Kafka in distributed systems as the backbone for communication between services and components. Kafka ensures that distributed systems can operate efficiently and reliably by providing a highly available, fault-tolerant, scalable messaging platform. It works for building microservices-based architectures, event-driven approaches, and other large-scale distributed applications.
Advantages of Using Kafka
Kafka offers several benefits that make it an attractive choice for various applications:
- High-throughput: Kafka can handle millions of events per second, making it suitable for large-scale data streaming and real-time analytics applications.
- Scalability: Kafka can quickly scale horizontally by adding more brokers to a cluster, allowing it to accommodate increasing workloads.
- Durability: Kafka stores messages on disk and replicates them across multiple brokers, ensuring high fault tolerance and data durability.
- Low latency: Kafka provides low-latency message delivery, making it suitable for real-time applications that require fast response times.
- Fault tolerance: Kafka offers a vital ability to withstand node or machine failures within the cluster. It ensures a stable, uninterrupted performance, safeguarding the system’s integrity and preventing potential disruptions.
- Batch processing: Kafka’s capabilities extends to batch processing scenarios, rivaling traditional ETL solutions. Its ability to persist messages enables it to adapt to diverse use cases, showcasing remarkable flexibility and utility in various data handling contexts.
What Is RabbitMQ Used For?
RabbitMQ, like Kafka, has a wide range of use cases thanks to its flexibility and support for various messaging patterns. Some common RabbitMQ use cases include:
- Application Integration
- Messaging
- Microservices Architecture
- Critical APIs
- PDF processing
- Database backup handling
RabbitMQ in Application Integration and Messaging
Developers often use RabbitMQ for application integration and messaging, where it acts as a reliable and flexible message broker that facilitates communication between different application components. Its support for multiple messaging patterns and protocols makes it suitable for integrating diverse systems, enabling applications to exchange data and events in a decoupled manner.
RabbitMQ in Microservices Architecture
You can also employ RabbitMQ in microservices-based architectures. It acts as the communication layer between different microservices. By providing a reliable and scalable messaging platform, RabbitMQ enables microservices to exchange data and events efficiently, ensuring smooth operation in complex systems.
Advantages of Using RabbitMQ
RabbitMQ offers several benefits that make it a popular choice for various applications:
- Flexibility: RabbitMQ supports multiple messaging patterns and protocols, making it adaptable to various application scenarios.
- Ease of use: RabbitMQ is known for its user-friendly design and comprehensive documentation, making it easy to learn and implement.
- Reliability: RabbitMQ provides reliable message delivery, ensuring messages reach their intended recipients even during failures.
- Rich routing capabilities: RabbitMQ’s exchange and binding mechanisms enable advanced message routing, allowing for sophisticated application architectures.
- Decoupling: Third-party systems can easily access and interact with messages, regardless of the original sender. This advantage allows for the efficient reuse of these messages across numerous projects.
- Redundancy: One of RabbitMQ’s key strengths lies in its ability to securely store messages within queues. This ensures that each message remains safely preserved until it has been fully processed and acknowledged, thus enhancing reliability and preventing data loss.
Related readings:
- Internet of Things Predictions for 2023: What Should We Expect?
- IoT in Healthcare: Key Trends & Usages
- Monolithic vs. Microservices Architecture: Pros and Cons
- Migrating Legacy Systems: Essential Stages and Tips from Pros
Kafkavs. RabbitMQ: Understanding the Differences
What is the difference between Kafka and RabbitMQ? While both RabbitMQ vs Kafka are popular messaging systems, they have different characteristics that make them suitable for various applications. Let’s compare Apache Kafka vs RabbitMQ based on such aspects as:
- Performance
- Scalability
- Message Durability
- Reliability
- Ease of Use and Setup
- Community Support and Ecosystem
- Routing and Messaging Patterns
- Protocol, Libraries, and Language Support
- Latency
| Feature | RabbitMQ | Apache Kafka |
| Description | A reliable, mature message broker for general use | A message bus tailored for high-volume data streams and message replay |
| Main Purpose | Facilitates communication and integration within and between applications; ideal for long-lasting tasks and dependable background jobs | Offers a platform for storing, accessing, and analyzing streaming data |
| License | Open Source: Mozilla Public License | Open Source: Apache License 2.0 |
| Implementation | Erlang | Scala (JVM) |
| Initial Release | 2007 | 2011 |
| Message Persistence | Stores messages until acknowledged by the recipient | Retains messages with the option to delete after a specified period |
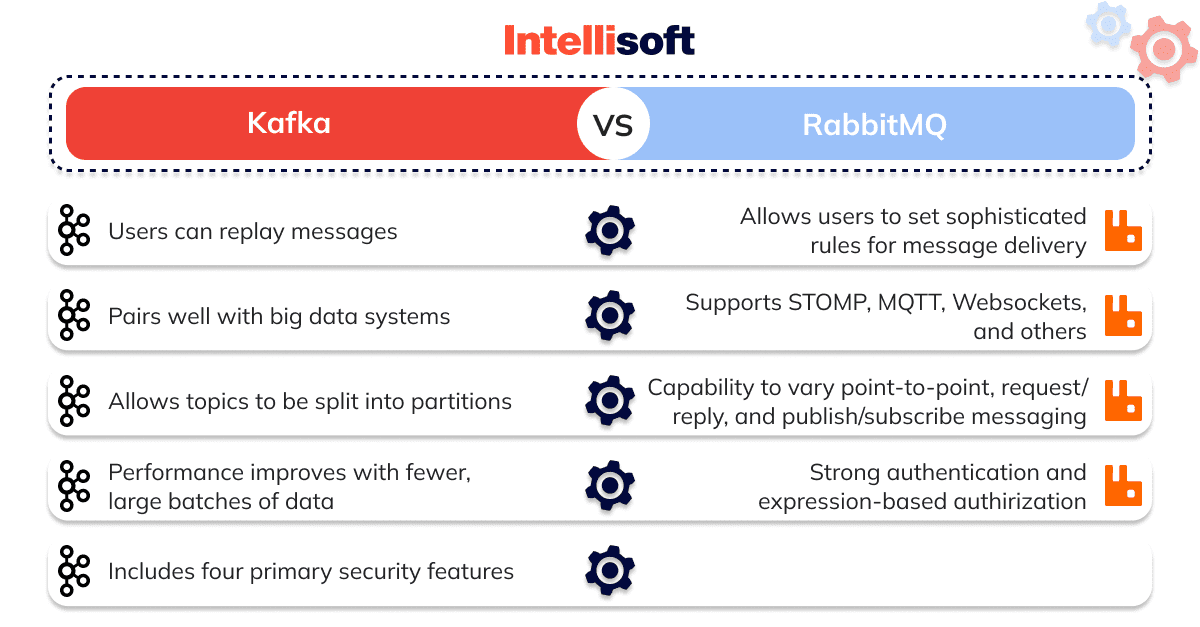
| Message Replay | Not supported | Supported |
| Message Routing | Allows flexible routing with information returned to consumer nodes | Routing must be handled via separate topics; flexible routing is not supported |
| Message Priority | Supported | Not supported |
| Monitoring | Built-in UI available for monitoring | Third-party tools such as CloudKarafka or Confluent required for monitoring |
| Language Compatibility | Supports most programming languages | Compatible with most programming languages |
| Authentication Security | Standard authentication and OAuth2 supported | Offers support for Kerberos, OAuth2, and standard authentication |
Performance Comparison
The difference between RabbitMQ vs Kafka is their performance. Kafka is known for its high-throughput capabilities and can handle millions of events per second. It makes it suitable for large-scale data streaming and real-time analytics applications. RabbitMQ, while less performant than Kafka in terms of throughput, can still handle many messages and is more than sufficient for numerous application scenarios.
Scalability Comparison
Another difference between RabbitMQ and Kafka is scalability. Both Kafka and RabbitMQ are scalable. Kafka achieves scalability through partitioning and horizontal scaling by adding more brokers to a cluster. RabbitMQ can also scale horizontally by clustering multiple RabbitMQ nodes together, but it relies on message sharding to distribute messages across nodes. While both systems are scalable, Kafka generally has an edge when handling massive workloads due to its partitioning capabilities.
Message Durability and Reliability
Kafka provides strong durability guarantees, as messages are persisted on disk and replicated across multiple brokers. It ensures high fault tolerance and minimal data loss in case of node failures. RabbitMQ also supports message persistence and replication, but its durability guarantees depend on the configuration, publisher confirmations, and acknowledgments.
Ease of Use and Setup
Developers often praise RabbitMQ for its ease of use, comprehensive documentation, and user-friendly management interface. It makes it relatively straightforward to set up, learn, and manage. On the other hand, Kafka has a steeper learning curve and can be more challenging to set up and control due to its distributed nature and more complex configuration options.
Community Support and Ecosystem
Both RabbitMQ and Kafka benefit from robust community support and extensive ecosystems. These ecosystems encompass various plugins, libraries, and integrations tailored for numerous platforms and programming languages. The strong backing from their respective communities contributes to the continuous development and improvement of these messaging systems. As a result, developers can rely on comprehensive documentation, support forums, and the availability of open-source contributions, which collectively enhance the capabilities and adaptability of RabbitMQ and Kafka in meeting the demands of diverse applications and use cases.
Routing and Messaging Patterns
RabbitMQ is known for its rich routing capabilities and support for various messaging patterns, including request/reply, point-to-point, and publish/subscribe. These exchange and binding mechanisms allow for advanced message routing, which can be helpful in complex application architectures.
Kafka primarily supports the publish/subscribe messaging pattern, focusing on high-throughput data streaming. While Kafka’s routing capabilities are less extensive than RabbitMQ’s, its partitioning mechanism enables parallelism and increased throughput.

Protocol, Libraries, and Language Support
Kafka supports numerous programming languages and libraries. It has built-in clients, which you can supplement with various community-contributed clients. These clients are available to Java and Scala, including the advanced Kafka Streams library, Go, Python, C/C++, and many other languages, in addition to REST APIs. Moreover, Kafka Connect features hundreds of pre-built connectors for seamless integration with external systems and applications.
RabbitMQ is compatible with many libraries and programming languages, including Java, Go, .NET, and more. It also supports such protocols as AMQP 0.9.1, AMQP 1.0, STOMP, and MQTT. Additionally, numerous client libraries are available for diverse programming languages and environments.
Latency
Difference between Kafka and RabbitMQ is also in latency. Kafka is designed for low-latency message delivery, making it suitable for real-time applications that require fast response times. RabbitMQ, while slower than Kafka in latency, still offers low-latency message delivery and is adequate for most application scenarios.
Kafka Strengths and Weaknesses
Let’s take a closer look at the strengths and weaknesses of Kafka, highlighting its key advantages and potential drawbacks to help you better understand when and where it shines.
Strengths of Kafka
Low Latency: Kafka provides low latency, often reaching up to 10 milliseconds. This speed is achieved by decoupling messages, allowing consumers to access and process them whenever they choose.
High Throughput and Scalability: Kafka is designed for high-performance, large-scale data streaming and can efficiently handle millions of events per second. Its distributed architecture enables it to scale horizontally by adding more brokers, making it suitable for handling massive data volumes.
Fault Tolerance and Durability: Kafka ensures data durability by replicating messages across multiple broker nodes. If a broker fails, another broker in the cluster can take over and continue processing the messages, providing fault tolerance and ensuring data availability.
Log-based Data Storage: Kafka employs a log-based storage system, which allows it to store and process data streams in a sequential and immutable manner. This approach is highly efficient for time-series data and event-driven applications, facilitating real-time data analysis.
Stream Processing: Kafka provides native stream processing capabilities through its Kafka Streams library, allowing developers to build powerful real-time data processing applications without additional frameworks or tools.
Weaknesses of Kafka
Complexity: Kafka’s architecture and configuration can be complex and challenging for newcomers. Its learning curve may be steep for those who need to become more familiar with distributed systems and log-based storage concepts.
Limited Message Routing: Kafka primarily bases its routing capabilities on topic and partitioning. While this approach is suitable for many use cases, it may not be as flexible as the routing capabilities offered by other messaging systems like RabbitMQ.
Lack of Built-in Message Prioritization: Developers didn’t design Kafka to provide built-in support for message prioritization. It processes messages in the order they are received, which may not be ideal for applications that require prioritization based on message content or other factors.
Reduced Performance: Brokers and consumers that compress and decompress the data stream can impact the performance and throughput of Kafka. This process affects Kafka’s efficiency and influences its overall data processing capacity.
As you can see, Kafka’s strengths lie in its high throughput, low latency, scalability, fault tolerance, and stream processing capabilities, making it an excellent choice for large-scale, real-time data processing applications. However, it is wise to consider its complexity, limited message routing, lack of built-in prioritization, and potentially reduced performance when evaluating its suitability for specific use cases.
RabbitMQ Strengths and Weaknesses
Now it’s time to explore the strengths and weaknesses of RabbitMQ, outlining its key advantages and possible limitations to give you a clear picture of when it excels.
Strengths of RabbitMQ
Flexibility and Versatility: RabbitMQ supports many messaging patterns, such as point-to-point, publish/subscribe, and request/reply. Its versatility makes it suitable for various application requirements and communication needs.
Advanced Message Routing: RabbitMQ provides powerful message routing capabilities using exchanges and queues, allowing for content-based routing, fanout, and topic-based routing, which offers greater flexibility than other messaging systems.
Message Prioritization: RabbitMQ supports built-in message prioritization, enabling applications to process high-priority messages before lower-priority ones, which can be beneficial when prioritizing specific tasks.
Wide Range of Supported Protocols: RabbitMQ supports multiple messaging protocols, including AMQP 0.9.1, AMQP 1.0, STOMP, and MQTT. This broad support ensures interoperability with various systems and platforms, simplifying integration across diverse environments.
Weaknesses of RabbitMQ
Lower Throughput: RabbitMQ’s throughput may be lower than that of systems like Kafka, which developers designed mainly for high-performance data streaming. Although RabbitMQ can handle substantial message volumes, it may not be the best choice for applications requiring extremely high throughput.
Limited Horizontal Scalability: While RabbitMQ supports clustering for high availability, it does not scale as seamlessly as Kafka in terms of horizontal scalability. Adding more nodes to a RabbitMQ cluster may not always result in a linear increase in performance, which can be a limitation for large-scale applications.
Less Suitable for Data Streaming: RabbitMQ is primarily a message broker and is not explicitly designed for data streaming or log-based storage like Kafka. As a result, it may not be as well-suited for time-series data processing or event-driven applications requiring real-time data analysis.
Memory Pressure: RabbitMQ stores messages in memory, which can lead to memory pressure if many messages are queued or unacknowledged for an extended period. It may result in increased resource consumption and potential performance issues.
In summary, RabbitMQ’s strengths include its flexibility, advanced message routing, prioritization, and wide range of supported protocols, making it a versatile choice for various application types and communication needs. However, it is wise to consider its lower throughput, limited horizontal scalability, less suitability for data streaming, and potential memory pressure when assessing if RabbitMQ is suitable for specific use cases.
Choosing Between Apache Kafka vs RabbitMQ
When deciding between RabbitMQ and Kafka, it is essential to consider the specific requirements of your application. When making your choice for an open-source software platform, it would be wise to keep these factors in mind:
- Performance and Throughput: If your application requires exceptionally high throughput, Kafka may be the better choice due to its ability to handle millions of events per second.
- Scalability: Both RabbitMQ and Kafka are scalable, but Kafka generally has an edge when handling massive workloads due to its partitioning capabilities.
- Message Routing and Patterns: If your application requires advanced message routing or support for various messaging patterns, RabbitMQ may be the more suitable option.
- Ease of Use and Setup: RabbitMQ is generally easier to set up and manage, making it a more user-friendly option for those new to messaging systems or with less experience managing complex systems.
- Latency: If your application requires low-latency message delivery for real-time processing, Kafka may be the more suitable choice due to its design for fast response times.
- Protocol Support: If your application needs to integrate with various platforms and languages using different messaging protocols, RabbitMQ’s support for multiple protocols may make it a more flexible option.
- Reliability and Durability: Apache Kafka vs RabbitMQ provide message persistence and replication, ensuring reliable message delivery and fault tolerance. However, Kafka may offer stronger durability guarantees due to its distributed and replicated commit log service.
Ultimately, the choice between RabbitMQ and Kafka depends on your specific application requirements and priorities. It’s essential to carefully analyze the strengths and weaknesses of each messaging system and evaluate how well they align with your project’s goals and constraints.
Which is better: Kafka vs RabbitMQ vs ActiveMQ?
Let’s compare ActiveMQ vs RabbitMQ vs Kafka and their usages.
Kafka is renowned for its scalability, high performance, and ability to handle high-throughput workloads, making it well-suited for big data use cases and streaming applications.
RabbitMQ is praised for its speed, ease of configuration, and intuitive interface, making it a good choice for scenarios where a lightweight, easy-to-deploy message broker is needed. It’s particularly well-suited for traditional messaging, job queues, and scenarios requiring complex routing, message acknowledgment, and delivery confirmation.
ActiveMQ is appreciated for its efficiency and ease of use, with strong support for various messaging protocols and patterns. It is a good choice for enterprises looking for a robust, open-source message broker that can handle a variety of communication scenarios.
Ultimately, the choice between RabbitMQ vs Kafka vs ActiveMQ depends on your project’s requirements:
- Use Kafka for high-volume, high-throughput, and real-time processing needs.
- Opt for RabbitMQ if you need a more traditional message broker with advanced routing capabilities.
- Choose ActiveMQ for a versatile and reliable messaging solution that supports a wide range of protocols and patterns.
The same goes when comparing RabbitMQ vs Kafka vs Redis.
Choosing between RabbitMQ vs Kafka vs Redis depends on your specific needs, as each technology serves different purposes in the realm of messaging and data processing:
RabbitMQ is widely used for queueing and message brokering. It’s ideal for scenarios where you need complex routing, message queuing, and delivery confirmations. It’s praised for being straightforward and easy to manage data flow.
Kafka is designed for high-throughput, distributed messaging and streaming data. It excels in scenarios that require handling large volumes of data in real-time, providing durability and fault tolerance. Kafka is often chosen for its scalability and performance in processing and distributing large streams of records.
Redis, while not a message broker like RabbitMQ or Kafka, is an in-memory data store used as a database, cache, and message broker. It supports various data structures and is known for high performance and low latency. Redis is suitable for caching, session management, pub/sub messaging systems, and as a fast, in-memory datastore.
Thus, when selecting between Kafka vs RabbitMQ vs Redis:
- Choose RabbitMQ for complex messaging patterns and lightweight message brokering.
- Opt for Kafka for large-scale message processing and streaming data applications.
- Use Redis for high-performance caching, quick data access, or when you need an in-memory datastore with pub/sub capabilities.
Real-World Scenarios
Let’s examine some real-world scenarios of how to use Apache Kafka and RabbitMQ and when to use Kafka vs RabbitMQ to address various use cases effectively.
RabbitMQ Use Cases
Complex Routing: RabbitMQ is an excellent choice for routing messages among multiple consuming applications, such as in a microservices architecture. Its consistent hash exchange can balance load processing across a distributed monitoring service, and you can use alternate exchanges to route specific portions of events to particular services for A/B testing.
Legacy Applications: You can also deploy RabbitMQ using available plugins (or by building your own) to connect consumer applications with legacy systems. For instance, you can communicate with JMS applications using the Java Message Service (JMS) plugin and JMS client library.
Kafka Use Cases
Tracking High-throughput Activity: Kafka excels at tracking high volume, high throughput activities such as monitoring website activity, ingesting data from IoT sensors, keeping track of shipments, or overseeing hospital patients.
Stream Processing: You can use Kafka to implement application logic based on event streams. For example, you can track the average value of an event lasting several minutes or maintain a running count of event types.
Event Sourcing: Kafka supports event sourcing, where the system stores the changes to an application state as a sequence of events. In a banking application, for instance, if an account balance becomes corrupted, you can use the stored transaction history to recalculate the balance.
Log Aggregation: You can also employ Kafka to collect and store log files in a centralized location, making it easier to manage, analyze, and monitor logs across your infrastructure.
As you can see, RabbitMQ and Kafka have particular use cases where they shine. RabbitMQ is ideal for complex routing and integration with legacy applications, while Kafka excels in high-throughput activity tracking, stream processing, event sourcing, and log aggregation.
Understanding these specific use cases can help you make the right choice when selecting the suitable messaging system for your project.
Alternatives to Kafka and RabbitMQ
While Kafka and RabbitMQ are two of the most popular messaging systems, the market offers some options that could better suit your specific requirements. Let’s review some notable alternatives and provide a high-level comparison.
MuleSoft Anypoint Platform
MuleSoft Anypoint Platform is an integration platform (iPaaS) service that offers a wide range of tools and services for connecting applications, data, and devices. It provides an event-driven architecture for messaging and supports advanced data transformation and mapping. Anypoint Platform is suitable for applications that require complex integrations and data transformations.
Anypoint Platform focuses more on integration and data transformation than Kafka and RabbitMQ. While it does offer messaging capabilities, its primary strength lies in its comprehensive integration features. The platform may be more appropriate for organizations that require extensive integration and data transformation capabilities.
IBM MQ
IBM MQ is ideal for organizations that need a reliable and secure messaging system for mission-critical applications. It is a robust, enterprise-grade messaging middleware that supports a variety of messaging patterns, including publish/subscribe, point-to-point, and request/reply. It offers advanced security features, high availability, and integration with various applications and platforms.
IBM MQ is a more mature and feature-rich messaging system than Kafka and RabbitMQ. It is particularly well-suited for enterprise applications requiring advanced security and high availability. However, IBM MQ’s licensing and pricing model may not be suitable for all use cases, particularly if you have a smaller organization or a limited budget.
TIBCO Enterprise Message Service
TIBCO Enterprise Message Service (EMS) is a fully-featured messaging middleware that supports publish/subscribe, point-to-point, and request/reply communication patterns. It offers advanced message filtering, transformation, and integration with TIBCO’s suite of integration and analytics products. TIBCO EMS is a good choice for applications that require advanced messaging features and integration with other TIBCO products.
TIBCO EMS provides a comprehensive set of messaging features and is particularly well-suited for organizations already using other TIBCO products. However, there may be better options for organizations requiring a more lightweight or open-source messaging system, as it has a proprietary license and can be harder to set up and maintain.
Google Cloud Pub/Sub
Google Cloud Pub/Sub is a messaging service offered by Google Cloud Platform that supports publish/subscribe and point-to-point communication patterns. It provides at-least-once delivery, global messaging, and automatic scaling.
Google Cloud Pub/Sub is a managed service that can simplify deployment and maintenance. However, it is limited to the Google Cloud Platform ecosystem, and its pricing model may not be suitable for all use cases.
MuleSoft Anypoint Platform offers extensive integration capabilities, IBM MQ provides advanced security and high availability for enterprise applications, Google Cloud Pub/Sub can simplify deployment and maintenance, and TIBCO EMS brings a robust set of messaging features and strong integration with TIBCO’s suite of products. When considering RabbitMQ and Kafka alternatives, evaluating each messaging system’s characteristics, performance, and suitability for your specific application requirements is crucial. Each option has strengths and weaknesses, so carefully assess your needs before deciding.
Conclusion
In this article, we’ve explored the intricacies of RabbitMQ and Kafka, two leading messaging systems that have proven they are valuable for the industry. We’ve delved into their respective architectures, use cases, and strengths and weaknesses and examined some noteworthy alternatives.
To recap, RabbitMQ is a versatile message broker well-suited for applications that require advanced routing, flexible message processing, and ease of integration with various languages and protocols. On the other hand, Kafka shines in scenarios that demand high throughput, fault tolerance, and scalability, making it an excellent choice for real-time data streaming, log aggregation, and event sourcing.
When choosing between RabbitMQ, Kafka, or any of their alternatives, consider the specific requirements of your application and the trade-offs associated with each messaging system. For instance, you might opt for RabbitMQ when dealing with complex routing and microservices, while Kafka could be the go-to solution for high-volume event streaming.
Here are some of the main deciding factors when choosing between RabbitMQ and Kafka:
- Throughput
- Scalability
- Latency
- Message routing capabilities
- Ease of use
At IntelliSoft, we understand that selecting the right messaging system is crucial for building efficient, reliable, and scalable software solutions. As a full-stack software development company specializing in designing, developing, and deploying high-performance applications, we leverage the power of modern messaging systems like RabbitMQ and Kafka to ensure our clients’ projects meet their unique requirements.
If you want to harness the potential of RabbitMQ, Kafka, or any other messaging system for your next project, don’t hesitate to contact IntelliSoft. Our team is ready to help you craft a tailor-made solution that exceeds your expectations and sets your application up for success. For operating cost estimation, you can use our development team calculator.