Imagine your business as a growing metropolis. Each department, project, and system is like a bustling neighborhood, constantly generating new data – some structured, some messy, all vital to understanding how your city operates. But where do you store this ever-expanding sea of information? Traditional databases can feel like rigid filing cabinets, with everything needing to fit into neat, predefined boxes. What happens when your info doesn’t conform?
This is where the concept of a data lake comes into play. The definition of what is a data lake was coined by James Dixon in 2010. DL isn’t just another information storage solution – it’s an entirely new way to think about information. Picture an enormous, unfiltered body of water where information can flow freely in its raw, unprocessed form.
Structured spreadsheets, social media logs, customer interactions; everything flows into this lake without the need for immediate categorization. This freedom offers a solution to one of the most frustrating pain points companies face; how to manage overwhelming information variety and volume without hitting storage limits or losing flexibility.
At IntelliSoft, with our 15+ years of experience in software development, we’ve seen how the right data lake architecture can transform an organization. In this article, we’ll explore what is a data lake platform, guide you through what a data lake is, how its architecture supports modern information demands, exploring data lake use cases and real-world examples to help you thrive in today’s information-driven world.
Table of Contents
What is a Data Lake? Data Lake Explained
What is a data lake house? A DL is an advanced storage solution designed to handle vast amounts of raw, unprocessed information in its native format.
Unlike traditional databases that require information to be neatly organized and structured, a DL welcomes all kinds of information – structured, semi-structured, and unstructured. It’s a flexible, scalable environment where businesses can store everything from sensor information and social media posts to logs and spreadsheets.
This approach allows organizations to delay information processing until it’s needed, opening up possibilities for deeper analysis and more strategic decision-making.
What is a Data Lake and How Does Data Lake Work?
Data lakes are complex ecosystems that consist of multiple layers working in harmony to store, process, and analyze information. Let’s break down how these layers function to give your business the tools it needs to harness its full information potential. What is a data lake used for and how does it work?
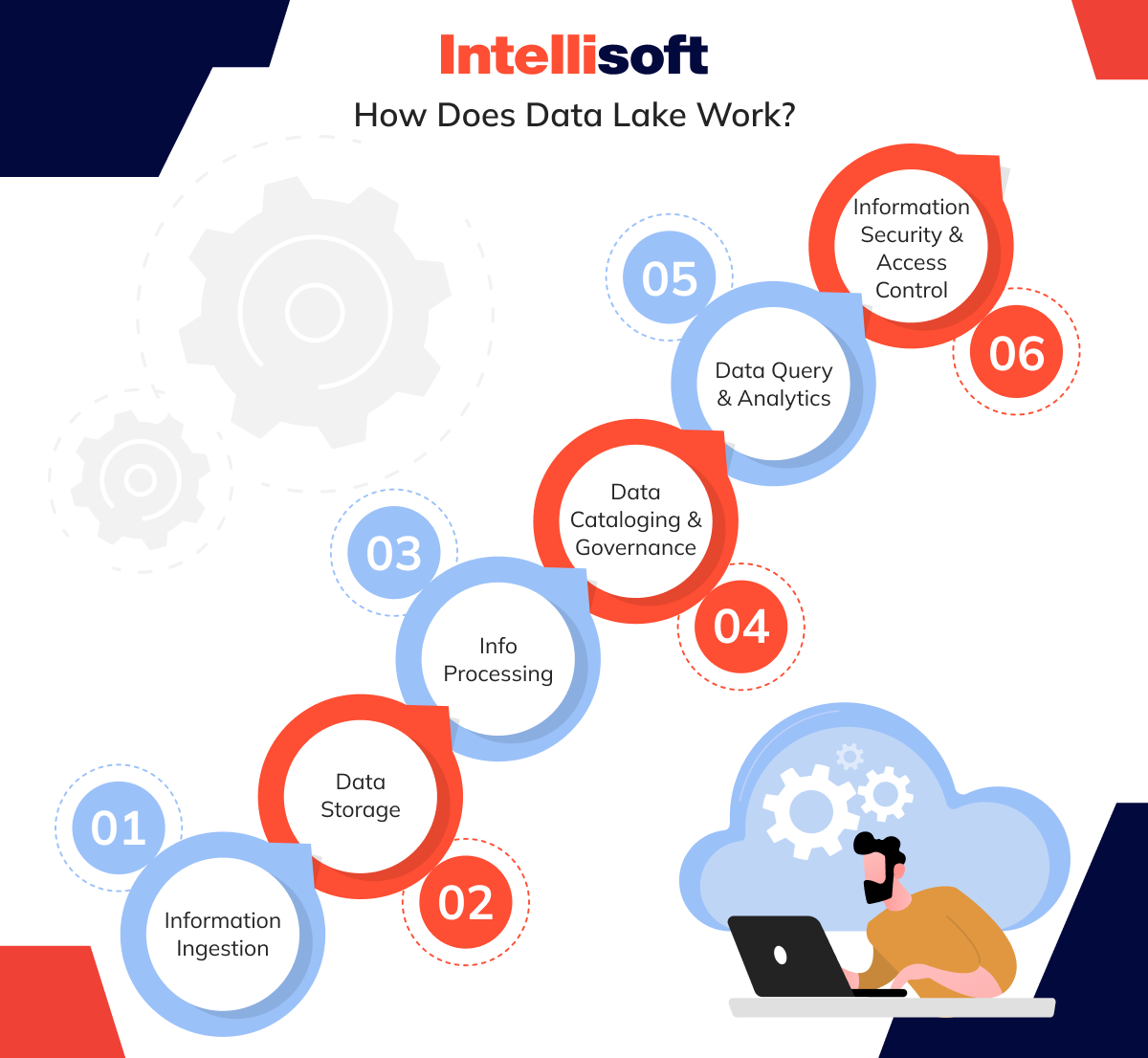
Information Ingestion
The journey begins with information ingestion. Here, various information types – from streaming information to batch processes – are funneled into the lake. This can include anything from real-time feeds to large sets of historical information. The beauty of a DL is that it can ingest information in its raw form, making it an incredibly versatile solution for organizations dealing with disparate sources.
Data Storage
Once the information enters the lake, it settles into the storage layer, which is designed to handle enormous volumes of information. Storage in a DL is highly scalable, allowing businesses to keep as much information as they need without worrying about structure or formatting upfront. This offers immense flexibility, particularly for companies gathering large datasets or operating in industries where information variety is high.
Info Processing
Raw information is only useful once it’s processed and transformed into something meaningful. DLs allow for on-the-fly processing, which means info can be organized and prepared when the need arises. Whether you’re performing real-time analytics or transforming information for long-term storage, the processing layer is designed to support various computational models, ensuring you can extract value from your information when you need it.
Data Cataloging and Governance
While DLs are known for their flexibility, they require solid information governance to prevent chaos. Info cataloging tools help track what information is stored and where, making it easier for users to search and retrieve relevant information. Proper governance policies ensure that information quality remains high, helping businesses avoid the common pitfall of creating a “information swamp” where information becomes disorganized and unusable.
Data Query and Analytics
One of the most powerful aspects of a DL is its ability to support advanced analytics. Using various querying tools, users can extract insights from information without moving or transforming it first. This makes DLs ideal for machine learning, predictive analytics, and other sophisticated applications that rely on large information sets to provide accurate insights.
information Security and Access Control
Information security and privacy are critical, especially when dealing with sensitive or regulated information. DLs incorporate strong access controls, encryption, and auditing capabilities to ensure only authorized users can interact with specific information sets. This layer helps businesses meet compliance requirements and safeguard against breaches.
How Data Flows in a DL
The magic of a DL lies in how effortlessly it handles the journey of raw information from collection to insight. It all starts with information ingestion, where information from countless sources – databases, IoT devices, APIs, and more – pours into the lake. What is the purpose of a data lake? What’s unique about DLs is that they don’t need information to be neat or structured. You can throw it in as-is, whether raw logs from sensors or social media interactions and the lake absorbs it all.
Once the information is ingested, it’s stored using scalable, cost-effective solutions, typically in the cloud. Think of this storage like a vast warehouse – there’s always room to grow, and you never have to worry about running out of space. This flexibility means you can stockpile all the information your business needs without stressing about limits.
However, raw information, while helpful, usually needs some cleaning up. That’s where information processing comes in. Whether in real-time for quick results, or batches for more detailed preparation, this step ensures your information is organized and ready for analysis whenever needed.
A good DL uses cataloging systems and metadata tagging to keep things from getting too chaotic. These tools act like a roadmap, helping you quickly find and manage the needed information. It’s how businesses prevent the lake from turning into a disorganized “information swamp.”
When it’s time to analyze the information, you can dive right in using a range of tools – whether you prefer SQL queries, BI platforms, or machine learning frameworks. The beauty of a data lake is that you can query and analyze information without having to move or reshape it first. This makes it easy to extract meaningful insights on the fly.
Of course, security is a top priority throughout this process. Strict access controls, encryption, and audit trails ensure that only authorized users can access sensitive information, giving you peace of mind and ensuring compliance with regulations.
Text: Need help from data analysis experts?
CTA: Learn more
Link: https://intellisoft.io/data-analytics-services/
When Does an IT Project Require a Custom Data Lake?
As businesses grow and their information needs become more complex, traditional storage and analytics systems often hit their limits. In such cases, a custom DL can be the answer. But when exactly does an IT project benefit from building a DL? Below, we explore the critical scenarios where implementing an information lake becomes not just valuable but essential. By diving into real-world examples, we’ll see how companies have harnessed the power of information lakes to meet their growing needs.

Large Volume of Data
When dealing with massive amounts of information, traditional storage systems can easily become overwhelmed.
Take Netflix, for instance. Every day, the streaming giant collects enormous volumes of information from user activity – everything from viewing habits to search queries. A custom DL allows Netflix to store all of this raw information in its native format without worrying about storage capacity limits or immediate processing. This enables the company to analyze historical information at any time and discover long-term patterns in viewer behavior.
Suppose your project faces similar challenges, where vast amounts of information must be stored and analyzed over time. In this case, a custom DL can offer the scalability and flexibility required to keep everything running smoothly.
Variety of Data Types
Data doesn’t come in a single format – it’s a mix of structured information like sales numbers, semi-structured information like JSON files, and unstructured information like emails or social media posts. Imagine a large retail company like Walmart, which deals with diverse information types from online transactions, supply chain logistics, and customer reviews. By implementing a DL, Walmart can store and manage this wide variety of information without needing to convert it into a uniform format first.
For any IT project that involves handling diverse information types, a custom DL allows for the storage of everything in one place, enabling deeper analysis across all aspects of business operations.
High-Volume Streaming Data
In industries where real-time information is critical, such as in finance or IoT-based systems, high-volume streaming information is a major challenge. A prime example is Tesla, which collects real-time information from its fleet of vehicles, monitoring everything from speed and location to battery levels. A custom information lake enables Tesla to store this streaming information continuously and process it for performance analytics, predictive maintenance, and software updates.
For projects where real-time decision-making is crucial – whether it’s monitoring stock prices or IoT sensor information – building a DL can provide the infrastructure to ingest and process high-speed information streams efficiently.
Advanced Analytics and Machine Learning
DLs are indispensable when it comes to advanced analytics and machine learning. Google, for example, uses custom information lakes to feed its machine learning algorithms with vast amounts of information, enabling everything from better search results to personalized content recommendations. In this scenario, raw information from countless sources is stored in the lake and processed on demand, allowing information scientists to experiment with different models and information sets.
Suppose your IT project requires advanced analytics or the development of machine learning models. In that case, a custom information lake can serve as a playground for innovation, allowing you to tap into all available information without constraints.
Integration of Multiple Data Sources
When your project relies on integrating data from various sources – be it databases, APIs, or external data providers – a DL simplifies this process. Take Airbnb, for instance. The company pulls in data from various sources, including user activity, property listings, and external weather APIs, to optimize pricing models and improve customer experiences. With a custom information lake, Airbnb can ingest and store information from all these sources in real time, providing a unified view of their entire operation.
If your project involves pulling information from multiple systems, a data lake ensures seamless integration, helping you get a full picture of your operations.
Cost-Effective Long-Term Storage
Sometimes, you don’t need to analyze info right away, but you do need to store it for potential future use. Healthcare organizations, for example, often need to store patient info for many years due to regulatory requirements. A custom DL offers a cost-effective solution for long-term storage, as businesses can store info at a lower cost compared to traditional infobases while keeping it readily accessible for future analysis.
If your project involves archiving large amounts of info for long periods, a custom info lake can provide a more affordable and scalable storage solution than traditional methods.
Scalability
As your business grows, so does the amount of info you collect. Facebook is a perfect case in point. The platform processes an enormous and ever-growing amount of user-generated content – photos, posts, videos, and more – requiring a highly scalable storage solution. Facebook’s custom DL architecture allows it to scale as its info volume expands, ensuring that it can continue to support billions of users worldwide without hitting storage or performance bottlenecks.
If your IT project involves future growth and scalability, investing in a custom info lake ensures your info infrastructure can expand as your needs evolve.
Regulatory Compliance and Data Retention
Regulations such as GDPR and HIPAA require companies to store info securely and ensure its accessibility for a defined period. Take financial institutions like JPMorgan Chase, which are required to retain transaction info for years and ensure it remains protected. A custom DL allows companies to store sensitive information securely, with encryption and access control features that ensure compliance with strict regulatory standards.
If your project needs to meet compliance requirements, a custom DL can handle secure info retention while providing the necessary audit trails and access controls.
What Are Popular Platforms for Creating a Data Lake?
Choosing the right platform can feel like finding a needle in a haystack. Each platform brings its unique flair and strengths to the table, helping organizations wrangle vast amounts of data into actionable insights. Let’s dive into some of the popular data lake platforms that make data management not just feasible but also exciting:
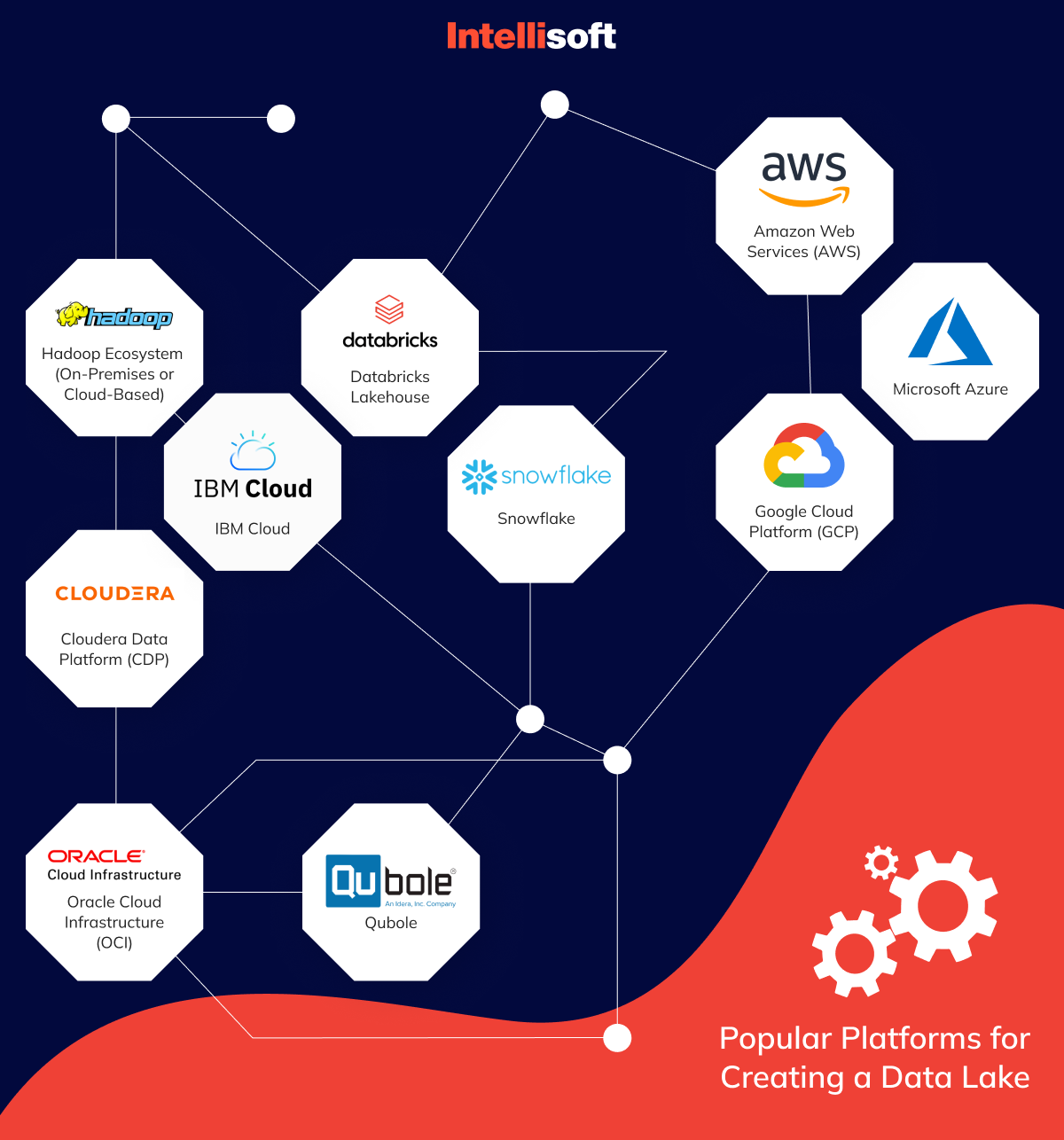
Amazon Web Services (AWS)
When it comes to info lakes, AWS is often the go-to choice for many businesses. Think of it as a vast ocean where you can store all kinds of data – from customer interactions to operational metrics – without worrying about running out of space. AWS makes it easy to scale up or down as your info needs change, thanks to its robust tools like Amazon S3 for storage and Amazon Redshift for analytics. With the added security and flexibility of a cloud environment, AWS turns info chaos into a well-orchestrated symphony of insights.
Microsoft Azure Data Lake Explained
Microsoft Azure is like a well-equipped toolbox for organizations looking to build their data lakes. Its Azure DL Storage offers a seamless way to store and analyze massive infosets. The beauty of Azure lies in its integration capabilities – if you’re already using Microsoft tools like Power BI or Azure Synapse, then creating a DL feels like second nature. Plus, Azure’s commitment to security ensures that your valuable info is always protected.
Google Cloud Platform (GCP)
What is a cloud data lake? GCP takes the complexity out of info lakes with its user-friendly interface and powerful tools. Imagine being able to tap into the vast resources of Google to store and analyze your info without worrying about the underlying infrastructure. With services like BigQuery, GCP allows businesses to run fast and interactive queries on large datasets, making it an attractive option for companies eager to unlock insights without the hassle of heavy lifting.
Snowflake
Snowflake is like the cool kid on the block that has captured everyone’s attention. It brilliantly combines DL and warehouse functionalities, allowing businesses to manage their info seamlessly. Its architecture separates storage from compute, which means you only pay for what you use. This flexibility is especially appealing for companies that experience fluctuating workloads. Snowflake’s ability to handle both structured and semi-structured info makes it a versatile choice for organizations wanting to consolidate their info sources.
Databricks Lakehouse
If you’re looking for a platform that feels like a modern playground for info scientists, Databricks Lakehouse is it. Built on Apache Spark, it combines the best of DLs and data warehouses, making it perfect for organizations focused on info science and machine learning. With its collaborative environment, teams can work together in real-time to analyze data, run experiments, and derive insights, all while enjoying the flexibility of cloud infrastructure.
Hadoop Ecosystem (On-Premises or Cloud-Based)
The Hadoop ecosystem might be seen as the seasoned veteran in the info landscape. It offers an open-source framework that allows organizations to build custom data lakes tailored to their specific needs. Whether you prefer to keep things on-premises or leverage the cloud, Hadoop provides the flexibility to manage your info your way. Its components, like HDFS for storage and Hive for querying, are tried-and-true tools that can handle large infosets with ease.
IBM Cloud
IBM Cloud is a reliable choice for businesses looking to integrate their DLs with advanced analytics and AI capabilities. With offerings like IBM Cloud Object Storage and Watson for AI-driven insights, IBM Cloud empowers organizations to harness the power of their info while ensuring compliance and security. It’s an excellent option for companies in regulated industries looking to leverage their data responsibly.
Cloudera Data Platform (CDP)
Cloudera’s CDP is all about balance, providing a solid foundation for info lakes that can thrive in both cloud and on-premises environments. It enables organizations to manage their data lifecycle with ease while ensuring strong governance and security. CDP stands out for its ability to integrate with existing Hadoop ecosystems, making it an ideal choice for companies that want to modernize their info operations without starting from scratch.
Oracle Cloud Infrastructure (OCI)
For organizations already invested in Oracle applications, OCI is a natural choice for building a DL. With services designed for both storage and analytics, OCI allows businesses to manage their info effectively while benefiting from Oracle’s robust security features. This platform is particularly appealing to those looking for seamless integration across their existing enterprise systems.
Qubole
Qubole stands out as a cloud-native solution that simplifies DL management. With its user-friendly interface and support for multiple cloud providers, Qubole allows organizations to focus on deriving insights rather than managing infrastructure. Its auto-scaling capabilities mean that businesses can easily adapt to changing data workloads, making it a flexible option for today’s dynamic info landscape.
Related Readings:
- Things to Know About Data Processing Agreement (DPA)
- Legal Requirements for Storing Data: Key Insights for Storing User Data
- Making Sense of Databases: How to Choose the Right One
- Big Data Security Intelligence: What You Need to Know
- Machine Learning vs Predictive Analytics: How to Choose
What Is a Tech Stack for Developing a Data Lake?
Creating a DL is like constructing a vibrant ecosystem where diverse data can flow, thrive, and be transformed into valuable insights. What is a data lake architecture? The tech stack plays a crucial role in ensuring that each component works harmoniously together, from capturing raw info to processing it and finally querying it for analysis. Let’s explore the essential layers of this tech stack that form the backbone of a robust data lake:
Data Ingestion Layer
The info ingestion layer serves as the entry point for all incoming info, gathering information from various sources like infobases, IoT devices, and web applications. This layer ensures that info flows smoothly into the DL, either through batch processes or real-time streaming.
Batch Ingestion Tools
- Apache Sqoop. A reliable tool for importing info from relational infobases like MySQL and Oracle into Hadoop.
- Apache NiFi. With its user-friendly interface, NiFi automates info movement between systems, making integration effortless.
- AWS Glue. This managed ETL service simplifies batch data integration and transforms info into a consumable format.
Streaming Ingestion Tools
- Apache Kafka. A powerful platform for real-time data streaming, ideal for building robust data pipelines.
- AWS Kinesis. Perfect for real-time data processing, Kinesis allows businesses to analyze streaming info seamlessly.
- Apache Flume. Designed to handle massive volumes of log data, Flume is crucial for capturing real-time events.
Data Storage Layer
Once the info is ingested, it finds its home in the info storage layer. This area must be scalable and durable, capable of accommodating a variety of info formats, whether in the cloud or on-premises.
Cloud Storage
- Amazon S3. A widely popular choice, S3 offers scalable object storage for raw info.
- Google Cloud Storage. Known for its scalability, this service provides reliable storage solutions for big data.
- Azure DL Storage (ADLS). Tailored for large-scale storage, ADLS is optimized for big data analytics.
On-Premises Storage
- Hadoop Distributed File System (HDFS). This distributed file system efficiently stores large datasets across multiple machines.
- Ceph. An open-source solution, Ceph is scalable and designed for large data lakes.
- GlusterFS. A versatile distributed file system ideal for on-premises setups.
Data Processing Layer
The data processing layer is where the magic happens – transforming raw info into actionable insights through batch and real-time processing.
Batch Processing
- Apache Hadoop (MapReduce). A staple in batch processing, Hadoop distributes info processing tasks across clusters.
- Apache Spark. Renowned for its in-memory computing, Spark accelerates analytics on large datasets.
- AWS EMR (Elastic MapReduce). A managed service that simplifies big data processing using Apache Spark and Hadoop.
Real-Time Processing
- Apache Flink. Known for its low-latency processing, Flink excels in handling real-time data streams.
- Apache Storm. A robust framework for processing data in real-time at scale.
- AWS Lambda. With its serverless architecture, Lambda enables quick data processing based on event triggers.
Data Cataloging and Metadata Management
Effective data management is crucial for ease of access and governance. This layer organizes and manages metadata and schemas, making it easier to navigate the data lake.
- Apache Atlas. This tool provides robust metadata management and data governance capabilities.
- AWS Glue Data Catalog. Automatically catalogs metadata for data stored in various AWS services.
- Microsoft Azure Data Catalog. A fully managed service designed for data cataloging and metadata management in Azure.
Data Query and Analytics Layer
Once info is stored, the next step is to analyze it using various tools tailored for querying and deriving insights.
SQL Query Engines
- Presto (Trino). A distributed SQL engine that enables querying large datasets across DLs.
- Apache Hive. Offers SQL querying capabilities for data stored in HDFS, making it user-friendly for analysts.
- AWS Athena. A serverless service that allows users to query info in S3 using standard SQL.
Machine Learning and Analytics
- TensorFlow / PyTorch. These frameworks enable machine learning and deep learning capabilities using info from the lake.
- Jupyter Notebooks. Ideal for interactive data analysis and visualization, providing a flexible environment for data scientists.
- Databricks. Built on Apache Spark, Databricks offers a unified platform for big info and machine learning.
BI Tools
- Tableau. A popular info visualization tool that helps users analyze data from the lake effectively.
- Power BI. Microsoft’s BI tool that integrates seamlessly with Azure DL Storage for enhanced analytics.
- Looker. A cloud-native BI platform for querying and visualizing info with ease.
Security and Data Governance
Security and governance are paramount in managing access and ensuring compliance. This layer protects sensitive info and ensures it is used responsibly.
Security
- AWS IAM (Identity and Access Management). Controls permissions and access to AWS resources, ensuring info security.
- Apache Ranger. Provides centralized security management for Hadoop clusters.
- Azure Active Directory. Facilitates identity and access management in Azure environments.
Data Governance
- Apache Atlas. Ensures robust governance, including info lineage tracking and classification.
- Collibra. A comprehensive info governance tool that helps manage info quality and compliance.
Encryption
- AWS Key Management Service (KMS). Manages encryption keys for data at rest in AWS S3.
- Azure Key Vault. Securely manages cryptographic keys and secrets for Azure services.
- HashiCorp Vault. A versatile tool for managing secrets and encrypting sensitive info across different environments.
Data Lake Orchestration and Workflow Management
This layer ensures the smooth flow of info across your lake, coordinating ingestion, processing, and storage.
- Apache Airflow. An open-source tool for scheduling and monitoring workflows.
- AWS Step Functions. Orchestrates AWS services into serverless workflows.
- Azure Data Factory. Automates info pipelines across systems and cloud platforms.
Monitoring and Logging
Monitoring tools provide insight into your data lake’s performance and health, essential for identifying issues and ensuring security.
- AWS CloudWatch. Monitors AWS resources and applications.
- Prometheus. An open-source system for collecting infrastructure metrics.
- ELK Stack. Aggregates info for real-time monitoring and analysis.
Example Tech Stack for a Cloud-Based DL
A typical cloud-based info lake uses flexible, scalable tools:
- Data Ingestion. AWS Kinesis, AWS Glue.
- Data Storage. Amazon S3.
- Data Processing. AWS EMR, Apache Spark.
- Data Querying. AWS Athena.
- Security. AWS IAM, AWS KMS.
Example Tech Stack for On-Premises DL
For organizations needing full control over data, here’s a common on-premises setup:
- Data Ingestion. Apache NiFi, Apache Flume.
- Data Storage. HDFS, Ceph.
- Data Processing. Apache Hadoop, Apache Spark.
- Data Querying. Apache Hive, Presto.
- Security. Apache Ranger, Apache Atlas.
What Are the Alternatives of Data Lake in Software Development?
While DLs are powerful for handling large-scale, diverse datasets, there are other solutions developers use depending on their specific needs.
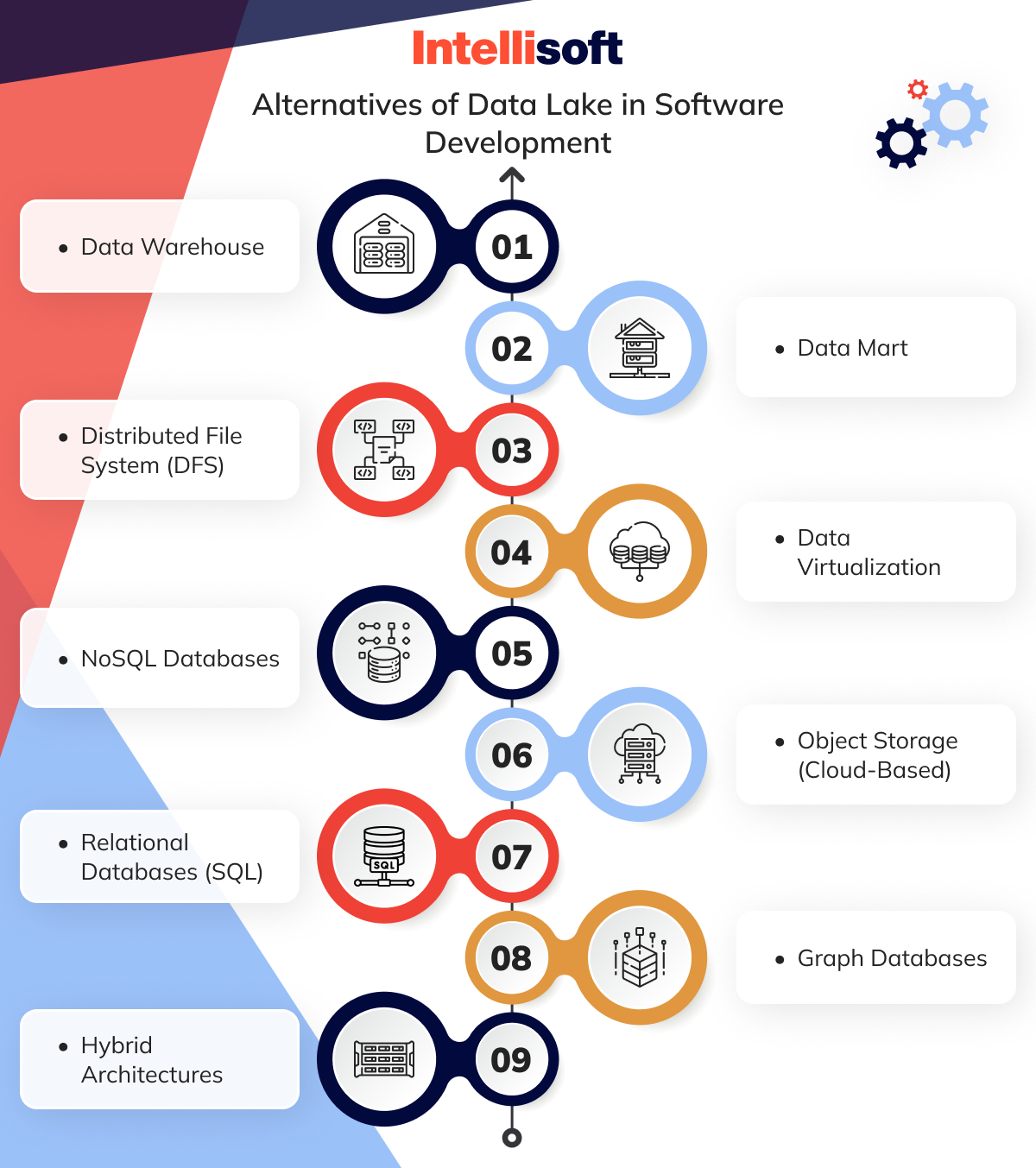
Data Warehouse
What is a data lake vs data warehouse? A data warehouse is a centralized repository designed to store large volumes of structured info from multiple sources, optimized for reporting and analytics.
Best For
Businesses needing high-speed querying for structured info, especially in industries like finance and retail.
Advantages
Delivers fast, reliable queries and reports; enforces strong data consistency and governance. It’s ideal for running complex queries on structured datasets.
Disadvantages
What is the difference between a data lake and a data warehouse? A data warehouse is expensive to implement and maintain, and less flexible with unstructured or semi-structured info. Scaling storage and compute power can be challenging.
Data Mart
A smaller, targeted version of an info warehouse, typically built for a specific business unit or department.
Best For
Teams or departments that need rapid access to relevant, business-specific info without accessing the entire company’s dataset.
Advantages
Cost-effective and quicker to implement than a full-scale data warehouse, allowing for more focused insights.
Disadvantages
Risks of info silos and duplication of information across different marts. Limited integration with broader enterprise info.
Distributed File System (DFS)
A system that distributes files across multiple machines to store large volumes of info, usually associated with big info frameworks like Hadoop.
Best For
Companies dealing with massive datasets, such as those involved in big data analytics or large-scale info engineering.
Advantages
Highly scalable and fault-tolerant, with the ability to store petabytes of info across clusters. Ideal for info-intensive applications like machine learning.
Disadvantages
Complexity in management and troubleshooting; not optimized for real-time queries and often slower compared to relational databases for certain tasks.
Data Virtualization
An abstraction layer that provides unified, real-time access to info across multiple sources without physically moving the info.
Best For
Organizations that require real-time integration of info from disparate sources, without the need for a physical info repository.
Advantages
Reduces data duplication and storage costs since the info isn’t moved or replicated. Provides a unified view across various info sources.
Disadvantages
Potential performance bottlenecks when querying large datasets, as it retrieves info in real-time. May lack advanced query support for complex info transformations.
NoSQL Databases
What is a data lake vs database? NoSQL Databases is a class of databases that provide schema flexibility, horizontal scalability, and are optimized for unstructured and semi-structured data.
Best For
Applications with rapidly changing or unstructured info (e.g., social media, IoT, or content management systems).
Advantages
Highly scalable, supports a wide range of info formats (documents, key-value, graph, etc.), and can handle high volumes of unstructured data.
Disadvantages
Limited support for ACID transactions and complex querying, making it less suitable for systems requiring high info integrity.
Object Storage (Cloud-Based)
Cloud-based storage systems designed for handling large volumes of unstructured info, such as media files, backups, and large datasets.
Best For
Businesses needing scalable, cost-effective storage for unstructured info, such as media companies or those dealing with large-scale backups.
Advantages
Nearly infinite scalability, low cost, and highly durable. It’s excellent for long-term info storage, especially for large, unstructured datasets.
Disadvantages
Performance can be slower compared to traditional storage when querying structured info or running analytics.
Relational Databases (SQL)
Traditional databases that store info in predefined tables and support SQL querying for structured data management.
Best For
Applications requiring high info integrity and complex queries, such as financial systems, ERPs, or CRM systems.
Advantages
Strong consistency, transactional support (ACID properties), and complex joins and relational data optimization.
Disadvantages
Less scalable for large datasets and difficult to handle unstructured or semi-structured info. Performance may degrade as info volume grows.
Graph Databases
A type of database optimized for storing and querying complex relationships between data points, represented as nodes and edges.
Best For
Social networks, recommendation engines, and fraud detection systems where relationships between entities are critical.
Advantages
Efficient at handling complex relationships and queries, ideal for highly connected info.
Disadvantages
Less efficient for traditional SQL queries or transactional info, with limited support for joins or aggregations compared to relational databases.
Hybrid Architectures
A mix of different info storage systems (e.g., DLs, data warehouses, and databases) to handle both structured and unstructured info efficiently.
Best For
Companies that deal with diverse data types (structured, semi-structured, unstructured) and require the flexibility to manage them across different platforms.
Advantages
Combines the strengths of multiple systems, providing flexibility to handle different info types and use cases.
Disadvantages
Complex integration and maintenance, requiring robust governance and orchestration to keep systems running smoothly.
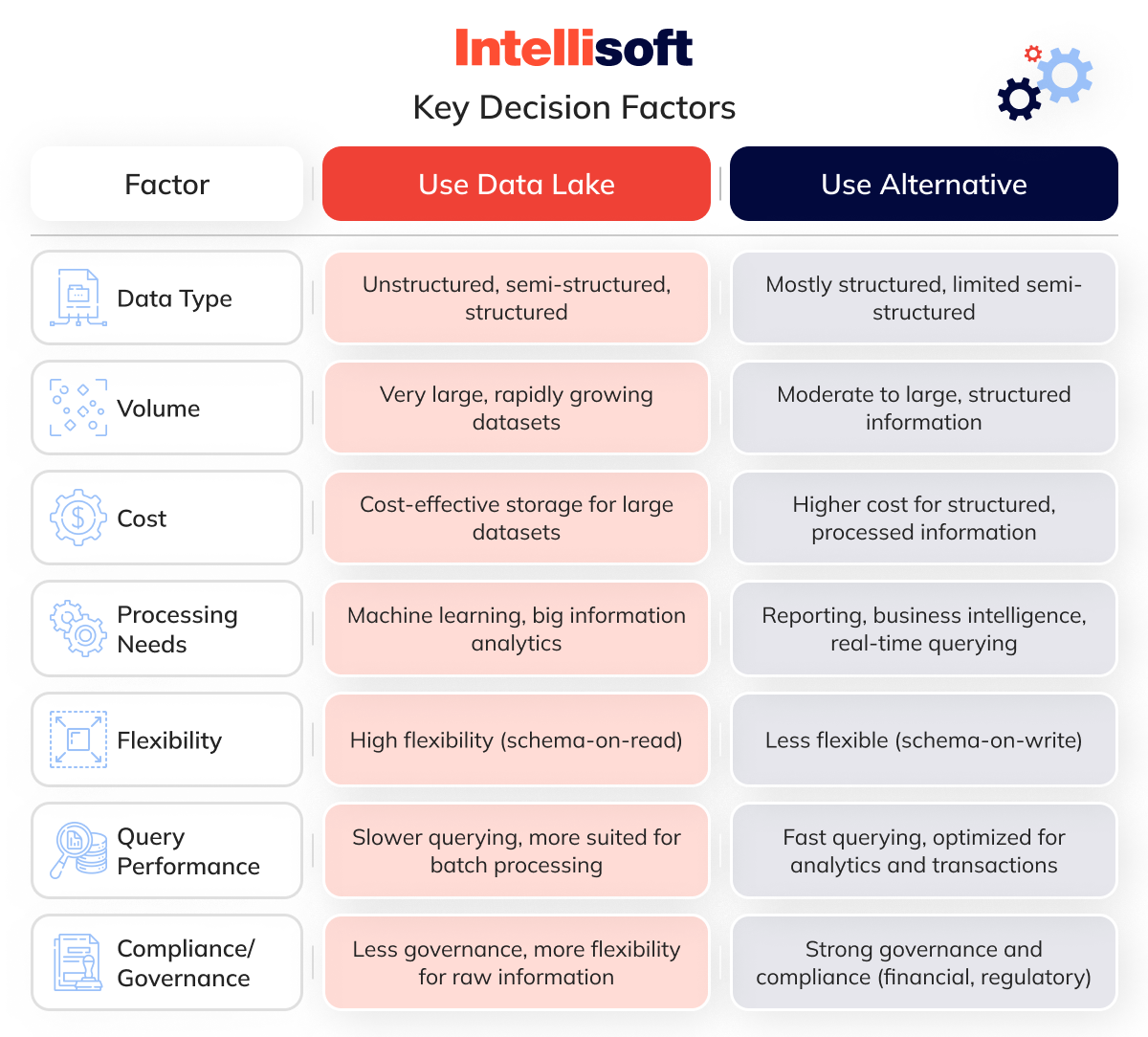
When to Use a DL and When to Go With Alternative Solutions?
Choosing between an info lake and its alternatives depends on your specific info needs. DLs are highly flexible, supporting vast, varied datasets, while alternative solutions offer more specialized capabilities. Let’s dive into when to use a DL and when alternative solutions might better fit your business.
When to Use a Data Lake
A DL is ideal for organizations dealing with massive volumes of diverse info (structured, semi-structured, and unstructured). You should consider an info lake when you:
- Need to handle big data. DLs are designed for storing vast amounts of info from multiple sources, especially unstructured info like logs, social media feeds, IoT data, and raw files.
- Plan to perform advanced analytics or machine learning. DLs are great for info scientists who need to run experiments, machine learning models, or deep learning on raw info.
- Want flexibility in data storage. Data lakes allow you to store all types of data without defining a schema in advance. You can transform it later as needed, providing more flexibility.
- Require cost-effective, scalable storage. Cloud-based information lakes, in particular, are highly scalable and cost-efficient for long-term information storage.
- Need a central repository. It can serve as a centralized hub for your organization’s information, accessible for analytics, BI, and machine learning without being confined to a rigid schema.
When to Use Alternative Solutions
There are scenarios where alternative solutions like data warehouses, information marts, or relational databases may be a better fit:
- Structured data with high querying needs. Suppose your information is well-structured and you need to perform complex, real-time queries. In this case, an information warehouse may be a better choice due to its performance and optimization for reporting.
- Department-specific insights. For business units that require quick, focused analytics without the need for enterprise-wide information, a data mart offers a more cost-effective and tailored solution.
- Transactional and real-time applications. For operational systems or applications that require high information integrity and support for ACID transactions, a relational informationbase (SQL) is the most reliable choice.
- Fast, low-latency querying. If you need real-time analytics and quick response times, solutions like NoSQL databases or distributed file systems (DFS) might suit your needs better than a DL.
- Hybrid environments. If your organization deals with both structured and unstructured data, but also has transactional needs, a hybrid architecture combining an information warehouse and a DL might offer the best balance.
Key Decision Factors
How Much Does It Cost to Develop a Data Lake?
The cost of developing an information lake can vary widely based on multiple factors. Here’s a breakdown of the main components that contribute to the overall cost:
Infrastructure Costs
- On-Premise Data Lake. Building an on-premise data lake involves substantial upfront costs for hardware, including servers, storage devices, and networking equipment. This can range from tens of thousands to millions of dollars, depending on the scale.
- Cloud Data Lake. Cloud solutions such as AWS, Microsoft Azure, or Google Cloud offer a more flexible pricing model. Costs are typically based on storage and compute resources used, ranging from a few hundred dollars per month for smaller projects to thousands for larger enterprises.
Software Costs
- Data Lake Tools. The software solutions you choose for building and managing your data lake can vary significantly in cost. While some tools are open-source and free, enterprise solutions with added features and support may incur licensing fees.
Development Costs
- Labor Costs. The complexity of the project influences labor costs. Outsourcing development can range from $50 to $150 per hour, depending on the region. Overall development could take several months, resulting in labor costs from $50,000 to over $500,000.
Information Ingestion and Transformation
- ETL Pipeline Costs. Setting up Extract, Transform, Load (ETL) pipelines and data processing workflows incurs additional expenses. Tools like Apache NiFi, Kafka, or Talend may have subscription costs, typically ranging from a few hundred to several thousand dollars monthly.
Ongoing Maintenance
- Monthly Fees. Ongoing maintenance costs include cloud usage, data security, backup, and support. Expect to pay ongoing monthly fees based on data size and processing requirements, especially for cloud-based data lakes.
Compliance and Security
- Regulatory Costs. Ensuring compliance with information regulations (such as GDPR or HIPAA) and implementing security measures like encryption can add to the overall costs.
Estimated Total Costs
- Small-Scale Cloud Data Lake. Approximately $5,000 to $50,000 for initial setup, with ongoing costs of a few hundred to a few thousand dollars monthly.
- Large Enterprise Data Lake. Development and infrastructure costs can exceed $500,000 to over $1 million, with ongoing cloud and maintenance costs of $10,000 or more per month.
Conclusion
Navigating the complexities of information management is akin to charting a course through uncharted waters. A well-architected information lake is more than just a storage solution; it’s a strategic asset that empowers businesses to transform raw information into actionable insights. Choosing between a data lake and alternative solutions involves careful consideration of your specific needs, goals, and budget.
Don’t leave your information potential untapped. Contact IntelliSoft today, and let’s explore how we can turn your data into your most valuable asset!
FAQ