Numerous organizations nowadays rely on big data—huge volumes of information that need to be stored and appropriately analyzed to make predictions about the future.
By 2027, the big data space is expected to reach $105 billion, with more than 97% of businesses investing in big data and AI. Predictive analytics and machine learning have risen as the two main players in this journey, often used synonymously, yet they are not the same.
If you’ve been choosing between predictive analytics vs machine learning, it’s high time to learn the main difference between the two and understand which model suits your business better. IntelliSoft, with over 13 years of experience in big data analytics, will help you navigate through this journey easily.
Table of Contents
What is Machine Learning?
Oftentimes, the difference between artificial intelligence vs. machine learning vs. predictive analytics is not clear, so let’s dive deeper into what ML and PA are.
Machine learning (ML)’s primary focus is the development of computer algorithms that improve themselves through repetition and experience using the data they receive.
Machine learning discovers specific patterns and trends in data sets. It can be used to predict future outcomes, classify images into categories, or detect trends.
Machine learning revolves around algorithms. These algorithms facilitate predictions and decisions made, designed to improve over time as they analyze more information, becoming more accurate and effective.
Examples of machine learning approaches include:
- Supervised Learning. The algorithm learns to establish relationships between inputs and outputs through this process. Once trained, it can accurately predict outcomes for new, unseen data points.
- Unsupervised Learning. In this case, unsupervised learning algorithms are trained on unlabeled data. Here, inputs have no categories or labels. These algorithms autonomously detect patterns by clustering or reducing the dimensionality of the dataset.
- Reinforcement Learning. Among the examples of machine learning, reinforcement learning is a method where algorithms learn to make decisions in an environment to get the best possible rewards. They learn by receiving feedback from the environment, either through rewards for good actions or penalties for bad ones. Through this ongoing process of trial and error, the algorithm gets better at making decisions and improving its overall performance.
How Does Machine Learning Work?
Understanding how machine learning works and the benefits of machine learning is essential to differentiate between ML and PA. Here’s a step-by-step guide that shows the process:
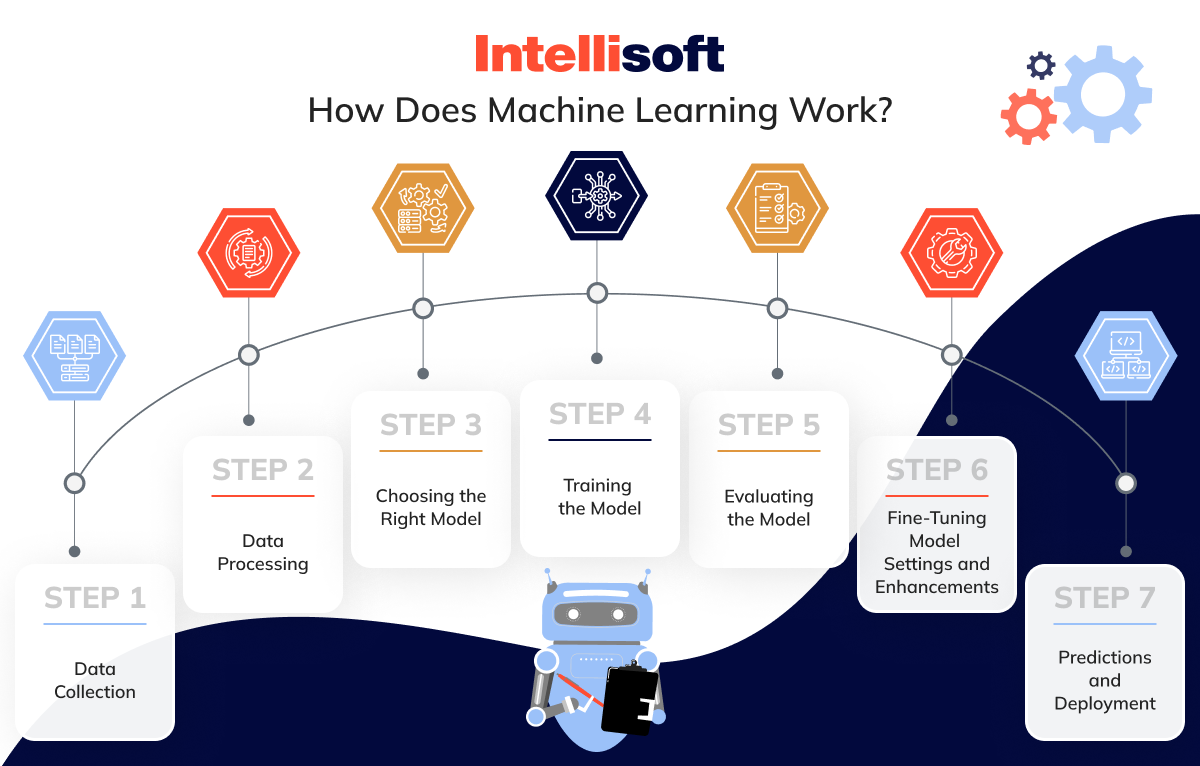
Step 1. Data Collection
The initial step in this process is data collection; without data, there would be no machine learning, so its quality and quantity influence how the model performs. Data is usually collected from images, databases, text files, audio files, and other sources, even web pages.
Then, the data is organized into suitable formats (CSV files or databases) to prepare it for machine learning. This process also ensures that the data is relevant to the specific cause or problem you’re solving.
Step 2. Data Processing
Data processing involves cleaning data, such as removing copies and correcting errors, handling missing data, and scaling the data to a standard format.
This process is meant to improve the quality of your data so that machine learning can interpret it correctly. By cleaning, transforming, and engineering features, data processing enhances the quality and usability of the data, ultimately improving the performance of the machine learning model.
Step 3. Choosing the Right Model
Once the data has been processed, the next step is to select the most appropriate machine-learning model for the task at hand.
The examples of machine learning models include:
- Linear Regression. This model is used to predict a continuous target variable based on one or multiple input features. This model assumes a linear relationship between the features and the target variable, rendering it applicable for various tasks, such as forecasting house prices using features such as size, number of rooms, and location.
- Decision Trees. Each division is guided by a decision node, ultimately leading to outcomes represented by the leaf nodes. Renowned for their intuitive nature and ease of interpretation, decision trees find utility in both classification and regression tasks across diverse domains.
- Neural Networks. These models are inspired by the human brain. Comprising interconnected layers of neurons, these models conduct simple computations at each neuron and pass the results to subsequent layers.
Step 4. Training the Model
Training the model involves using the processed data to teach the chosen machine learning algorithm how to recognize patterns and make predictions. During training, the algorithm keeps tweaking its inner workings to make its predictions closer to the actual targets in the training data. It does this by using techniques like gradient descent, which helps the model adjust its settings gradually in a way that reduces mistakes or errors.
The aim of the training is to teach the model to perform well on new data it hasn’t seen before, ensuring it can make accurate predictions. To accomplish this, the model needs to learn the important patterns and connections from the training data without simply memorizing specific examples or becoming too specialized. Overfitting happens when the model learns from irrelevant or noisy details in the training data, resulting in lower accuracy when faced with new data.
Step 5. Evaluating the Model
Once the model completes its training, it undergoes evaluation to gauge its performance and ability to generalize. Evaluation entails testing the model on a distinct dataset, termed the validation or test set, which remains unseen during training. This ensures an impartial assessment of how well the model fares on fresh, unfamiliar data.
The selection of the evaluation metric hinges on the specific goals and demands of the problem. It’s crucial to interpret the evaluation outcomes thoughtfully, considering factors such as the balance between precision and recall or the trade-off between false positives and false negatives.
Step 6. Fine-Tuning Model Settings and Enhancements
Hyperparameters are like knobs that adjust how a model learns and performs. They include settings such as learning rate, regularization strength, or the complexity of a model. Tuning hyperparameters means finding the best values to make the model work its best on new data.
Beyond tweaking hyperparameters, we can also use other tricks to make the model even better. These might involve picking the most important features, reducing the complexity of the data, or combining multiple models to make better predictions.
Step 7. Predictions and Deployment
Now, the model is ready to make predictions on new data. The trained model can be deployed into production environments, such as software applications, websites, or cloud-based services, to serve its intended purpose.
Consider the scalability, reliability, and maintainability of the model during deployment. Monitor its performance to ensure it continues to perform well as the data distribution evolves. Periodic retraining or updating of the model may be necessary to maintain its effectiveness in real-world applications.
Related Readings:
- Best Tech Stack for Optical Character Recognition Automation
- Top 10 Data Warehouse Software Tools for Your Business
- The Top 10 Programming Languages Powering AI and Machine Learning
- Predictive Analytics in Retail: Boosting ROI and Transforming Customer Experience
ML Use Cases
Here are some notable use cases and benefits of machine learning in different sectors:
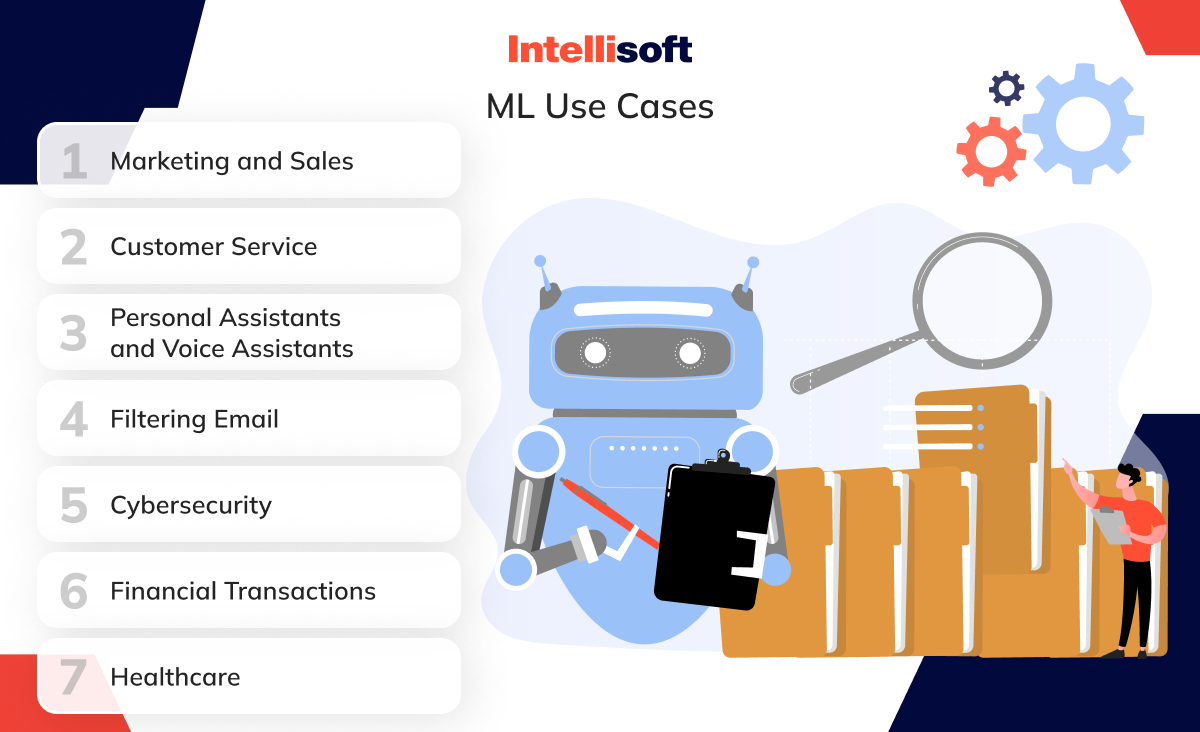
Marketing and Sales
In marketing and sales, ML is used for customer segmentation, allowing businesses to categorize customers based on behavior, demographics, and preferences. This segmentation is important for marketing campaigns and personalized messaging, optimizing conversion rates and customer satisfaction.
Customer Service
Machine learning is also used to analyze users’ feedback from social media and customer reviews on websites. When businesses analyze customer feedback, they can see satisfaction levels and decide what should be improved. Moreover, ML is also used in chatbots that provide instant assistance for customers, saving employees’ time and helping resolve issues as they arise, improving the quality of service.
Personal Assistants and Voice Assistants
Another use case of ML is personal assistants and voice assistants. These tools can respond to voice commands and queries instantly by using natural language processing (NLP) technologies. They interpret the input, analyze it, perform specific tasks, and take the needed information for the internet or databases.
Filtering Email
ML also can help filter emails to distinguish between real emails and spam or messages sent by bots. These algorithms analyze email content, information of the sender, and overall user behavior and sort the messages received. That’s an important feature for cybersecurity measures and improved inbox management.
Cybersecurity
In cybersecurity, machine learning algorithms are vital for spotting and stopping cyber threats like data breaches and malware attacks. They do this by examining network traffic, user actions, and system records. By recognizing patterns that signal suspicious behavior, these algorithms help companies act quickly to stop potential threats, safeguarding their systems and data from harm.
Financial Transactions
In the financial sector, ML is used for fraud detection, predictive analytics, and risk assessment. These models analyze fraudulent activities such as unauthorized access, identity theft, and overall patterns of fraudulent behavior.
Healthcare
In healthcare, ML is used for numerous purposes. For instance, healthcare organizations use ML models for disease diagnosis, personalized treatment planning, and patient monitoring.
What is Predictive Analytics?
There’s a considerable difference between machine learning and predictive analytics. PA includes various statistical techniques (ML, predictive modeling, data mining) and uses statistics to estimate future outcomes. In other words, by analyzing past data, predictive analytics helps understand what may happen in the future.
Predictive analytics is one of the four key types of analytics; the other three include descriptive analytics, diagnostic analytics, and prescriptive analytics. Predictive analytics includes diagnostic and descriptive analytics features as it examines historical data and why some trends happen.
Unlike other types of analytics, such as descriptive and diagnostic analytics, which focus on understanding past and present data to gain insights into what has happened and why, predictive analytics looks ahead to anticipate what may happen. One of the main benefits of predictive analytics is that it does not just analyze past events to provide actionable insights into future possibilities.
How Does Predictive Analytics Work?
Predictive analytics relies on predictive modeling and goes hand-in-hand with ML. There are two types of predictive models: Classification and Regression models.
Classification models predict class membership. Regression models, in turn, predict a number. Both models are made of algorithms that perform data mining and statistical analysis. All predictive analytics software solutions have these algorithms built in for making predictive models.
Here are some of the most commonly used predictive models and examples of predictive analytics:
- Decision Trees. Decision trees are popular predictive models that organize data into a tree-like structure of decisions and their potential outcomes. Each decision, represented by an internal node, is based on a specific feature of the data. Leaf nodes represent the predicted outcome or class label.
- Regression. These models look at how different things are related and use that information to make predictions. For example, they can help predict how sales might change based on factors like advertising spending or time of year. The models can be simple, like drawing a straight line between two points, or more complicated, taking into account many factors to make more accurate predictions.
- Neural Networks. They’re made up of layers of artificial neurons that process information and learn from it. These networks can look at lots of data and figure out patterns to make predictions or decisions. They’re really good at understanding complex relationships in data, which makes them useful for all kinds of predictions, like recognizing objects in images or predicting stock prices.
Other classifiers include:
- Time Series Algorithms. Time series algorithms are used to analyze sequential data points recorded over time. These algorithms are beneficial for forecasting future values based on past observations, such as stock prices, weather patterns, or sensor data.
- Clustering Algorithms. Clustering algorithms group similar data parts based on their features. These algorithms are often used for exploratory data analysis, customer segmentation, and anomaly detection.
- Outlier Detection Algorithms. Outlier detection algorithms identify data points that deviate significantly from the rest of the dataset. These outliers may represent errors in the data, anomalies, or rare events that warrant further investigation.
- Ensemble Models. Ensemble models combine multiple individual models to improve predictive performance and robustness. Techniques such as bagging, boosting, and stacking ensemble different models, leveraging each other’s strengths to achieve better results.
- Factor Analysis. Factor analysis is a statistical method used to identify underlying latent variables or factors that explain patterns in the observed data. This technique is often used to reduce dimensionality and identify key drivers of variability in the data.
- Naive Bayes. Naive Bayes is a probabilistic classifier based on Bayes’ theorem and conditional independence assumption between features. Despite its simplicity, Naive Bayes is often effective for text classification tasks, spam filtering, and sentiment analysis.
- Support Vector Machines (SVMs) work by finding the optimal hyperplane that separates data points into different classes. SVMs are effective for linear and non-linear classification tasks and are widely used in various domains, including image classification, text classification, and bioinformatics.
Predictive Analytics Use Cases
Predictive analytics is widely applied across diverse industries due to the benefits of predictive analytics, offering solutions to various challenges. Here are some common examples of predictive analytics:
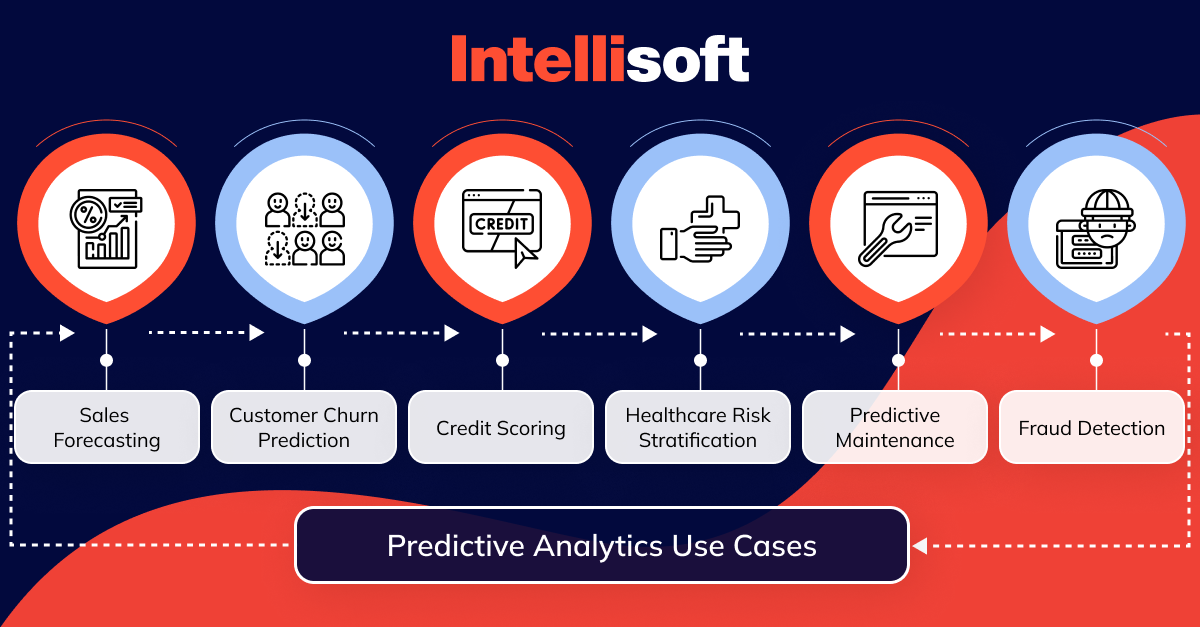
- Sales Forecasting. Businesses can optimize inventory management, production planning, and resource allocation by analyzing this data.
- Customer Churn Prediction. Predictive analytics identifies customers who are likely to cancel their subscriptions or leave the website without completing the purchase. By analyzing customer behavior, usage patterns, and engagement metrics, businesses can implement strategies to reduce churn rates.
- Credit Scoring. Predictive analytics are used to assess credit risk and predict the likelihood of loan default. Lenders can make informed decisions about extending credit by analyzing credit history, income levels, and economic indicators.
- Healthcare Risk Stratification. Predictive analytics stratifies patients based on their risk of developing certain diseases or medical conditions. By analyzing patient data, including medical history and lab results, healthcare providers can identify high-risk patients and implement preventive interventions.
- Predictive Maintenance. Organizations use predictive analytics to optimize maintenance schedules and reduce equipment downtime by predicting when machinery or assets are likely to fail. By analyzing sensor data and historical maintenance records, companies can schedule maintenance proactively, minimizing disruption and costs.
- Fraud Detection. Among the examples of predictive analytics, it also detects fraudulent activities and transactions in the banking, insurance, and e-commerce industries.
What Are the Key Differences Between Predictive Analytics vs Machine Learning?
Here’s the comparison between predictive analytics vs machine learning:

Now that you know about the main differences between data analytics and machine learning, let’s dive into the challenges that appear during the adoption of those technologies.
Challenges of Predictive Analytics
One of the main challenges of PA is the quality and availability of data. Since predictive analytics relies entirely on data, there should be no issues with the data, or it can lead to inaccurate results and unreliable predictions.
Moreover, one should have enough expertise in predictive analytics algorithms because selecting the appropriate features among all the variables is another challenge. It can be difficult to keep up with the computing power needed to analyze data properly as data grows.
Challenges of Machine Learning
ML has similar issues to PA. First, you should have good-quality data, or the system won’t learn properly and give accurate results. Moreover, you need a lot of computing power for the computer to analyze data and learn from it, and not all businesses have access to such computing power. Finally, it is challenging to ensure that the system does not learn a bias from the data; you should address these biases in training data and ensure complete fairness, which is a huge challenge.
How to Choose Between Predictive Analytics vs Machine Learning?
Here’s how to choose between machine learning vs predictive analytics:
Understanding the Nature of Your Problem
Before choosing between machine learning and predictive analytics, it’s crucial to understand the nature of your problem thoroughly. Consider whether your goal is to forecast future outcomes based on historical data patterns or to solve complex problems with intricate data relationships.
If your problem involves predicting future trends or events based on historical data, predictive analytics may be more suitable. On the other hand, if your problem requires handling complex data relationships and making autonomous predictions or decisions, machine learning techniques may be more appropriate.
Considering the Data Volume and Variety
Evaluate the volume and variety of your data when deciding between machine learning and predictive analytics. Machine learning techniques often require a significant amount of labeled or unlabeled data for training models, especially for complex problems or advanced algorithms such as deep learning. If you have large volumes of diverse data types, machine learning may be advantageous for handling this complexity. However, if your data is relatively structured and historical, and you aim to forecast future outcomes based on existing patterns, predictive analytics may suffice.
Evaluating the Complexity of the Models
Assess the complexity of the models required to address your problem. Machine learning models, particularly advanced techniques like deep learning, can handle intricate data relationships and nonlinear patterns but may require expertise in model development and computational resources.
Machine learning may be the better choice if your problem involves complex data relationships and you need highly accurate predictions. However, if your goal is to analyze historical data patterns and make straightforward forecasts, predictive analytics models may be simpler and more straightforward to implement.
Assessing the Availability of Resources
Consider the availability of resources, including data, expertise, and computational resources, when choosing between machine learning and predictive analytics. Machine learning techniques often require a higher level of expertise in algorithms, data preprocessing, and model evaluation, as well as access to computational resources for training complex models.
If you have the necessary resources and expertise, machine learning can offer powerful capabilities for addressing complex problems. However, if resources are limited, predictive analytics may be a more practical option, as it typically involves simpler models and techniques that are easier to implement.
Determining the Level of Automation Desired
Determine the desired level of automation for your problem-solving process. Machine learning techniques offer a high degree of automation once models are trained, making them suitable for tasks requiring real-time predictions or decision-making.
Machine learning may be preferable if you need automated systems that can make autonomous decisions based on data. However, suppose you require human intervention for interpretation and decision-making based on predictive insights. In that case, predictive analytics may be more suitable, as it focuses on analyzing historical data patterns rather than automating decision-making processes.
Conclusion
Now that you understand the difference between machine learning vs predictive analytics, it’s time to choose what you need most for your business. Do you need algorithms that develop themselves and improve over time through experience? Go for ML.
Predictive analytics is your perfect match if you need a system that uses stats and past data to make predictions about the future.
Maybe you must utilize both to grow your business and address your needs and requirements. In any case, you need a reliable tech partner to do that.
If you’ve been struggling to choose between the two and need assistance and guidance, contact IntelliSoft, and we will help you during this process.








