Information comes in various forms, including structured and unstructured formats. Structured data is organized and easy to analyze, while unstructured is more complex and doesn’t fit neatly into traditional databases. Understanding the differences between structured and unstructured data is crucial for effectively collecting, managing, and utilizing information.
In this article, we will delve into the characteristics and examples of structured semi structured and unstructured data, providing insights to help you make the most of the valuable information available.
Table of Contents
What Is Structured Data?
Structured information, which is usually quantitative information that is well-organized and can be easily understood by machine learning algorithms, has been a critical component in the development of technology. IBM created SQL as a programming language in 1974, which is specifically designed to manage structured information. With a relational database powered by SQL, businesses and users can efficiently input, search, and manipulate structured insights for various purposes.
Pros and Cons of Structured Data
Examples of structured insights include dates, names, addresses, credit card numbers, among others. Their benefits are tied to ease of use and access, making it straightforward for both humans and machines to search, retrieve, and analyze this information efficiently.
Pros
Here are the most valuable advantages of using structured information.
Easily used by machine learning (ML) algorithms
Structured insights is highly beneficial for machine learning applications due to its specific and organized architecture. This organization facilitates easier manipulation and querying of information, which are crucial processes in machine learning. The structured format ensures that information is consistently formatted and easily identifiable, allowing algorithms to quickly access and process the insights without the need for extensive preprocessing.
Easily used by business users
Structured information is particularly advantageous for business users because it does not require a deep understanding of complex information types or their underlying mechanisms. Even with just a basic knowledge of the subject related to the information, business users can access, interpret, and leverage this information effectively. The predictable format of structured information, such as tables with rows and columns, makes it straightforward for users to navigate and understand the information they are working with.
Accessible by more tools
Since structured information has been around longer than unstructured, there is a broader array of tools developed to handle it. These tools range from traditional relational database management systems to modern analytics software, which are designed to input, process, and analyze structured insights efficiently. The long history of structured information means that many legacy systems are also equipped to handle it, offering greater flexibility and options for data analysts and IT professionals.
Cons
However, there are two disadvantages to using structured information.
Limited usage
Structured data is designed with a specific architecture and predefined structure, which inherently limits its utility to its originally intended purposes. This rigidity can be a significant drawback in dynamic environments where the needs and demands are constantly evolving. The inflexible nature of structured information means that it is not well-suited for tasks or analyses that were not considered during its initial design, thereby limiting its overall versatility and application in diverse scenarios.
Limited storage options
Structured data is typically stored in systems with strict schemas, such as traditional relational databases or data warehouses. These storage systems require that all information conform to a predetermined format, which can pose significant challenges when information requirements change or evolve. Any modification to the insight structure necessitates comprehensive updates to the entire dataset, leading to considerable consumption of time and resources.
Structured Data Tools
Looking for a way to optimize your website and improve its search engine rankings? Structured information testing tools can help by identifying and fixing SEO errors, as well as checking if your site is using microdata or structured information markup. The right tool can make a big difference, so keep reading to learn about the best options available!

- OLAP. OLAP tools are designed to perform high-speed, multidimensional analysis, making it easier to manage and query large sets of information from unified, centralized stores. This type of system is particularly useful for businesses that need to analyze complex information from various dimensions quickly and efficiently.
- SQLite. SQLite implements a self-contained, serverless, zero-configuration, transactional relational database engine. This database system is ideal for environments where simplicity and minimal setup are crucial, such as in applications for mobile devices or small web applications. The absence of a server makes SQLite an excellent choice for applications that need to operate without requiring a complex database system.
- MySQL. MySQL is a robust database system that embeds information into mass-deployed software. It is especially useful in mission-critical, heavy-load production systems where reliability and performance are paramount. MySQL is widely used in web applications and serves as the backbone for many software systems requiring scalable, high-performance database solutions.
- PostgreSQL. PostgreSQL is a highly versatile database system that supports both SQL and JSON querying. It also offers compatibility with high-tier programming languages like C/C++, Java, and Python, making it a flexible choice for developers. PostgreSQL is suited for more complex database systems that require extensive information integrity and customization options. This system is widely favored in enterprises and professional environments that demand robust processing capabilities.
Use Cases for Structured Data
Here are four prominent examples of using structured information:
Customer Relationship Management (CRM)
CRM software leverages structured information by running it through analytical tools. These tools help create comprehensive datasets that uncover patterns and trends in customer behavior. This information is vital for businesses to tailor their marketing strategies and improve customer service.
Online Booking
The structured format of hotel and ticket reservation data is a classic example of structured and unstructured data use. This information includes essential details such as dates, prices, destinations, and more, arranged in a predefined “rows and columns” model. This structure allows for efficient processing and retrieval, making it easier for businesses to manage reservations and analyze booking trends.
Accounting
Structured insights are indispensable in the accounting sector. Accounting firms and departments utilize it to accurately process and record financial transactions. This information helps in maintaining detailed and accurate financial records, facilitating effective financial management and compliance with regulatory requirements.
E-commerce
E-commerce platforms extensively use structured data to manage inventory, track orders, and understand consumer purchasing behaviors. Information like product IDs, categories, prices, and stock levels are stored in a structured format, enabling seamless operations and strategic planning.
What Is Unstructured Data?
Unstructured data, which falls into the category of qualitative information, presents a challenge for conventional insight tools and methods due to its lack of a predefined model. Non-relational (NoSQL) databases are the most effective way to manage unstructured information, as they are designed to handle this type of information. Another approach to managing unstructured information is to utilize data lakes, which store insights in their raw form.
The significance of unstructured information is growing rapidly. Recent forecasts suggest that unstructured data accounts for over 80% of all enterprise data, and 95% of businesses have prioritized unstructured data management.
Pros and Cons of Unstructured Data
Examples of unstructured information encompass a wide range of sources such as text, mobile activity, social media posts, Internet of Things (IoT) sensor insights, and more. Unstructured data offers benefits in terms of flexibility in format, fast processing, and reduced storage requirements. However, effectively utilizing this type of information requires expertise and access to sufficient resources, which can pose challenges.
Pros
Using unstructured data has valuable advantages:
- Native Format. Unstructured information is stored in its native format, leaving it undefined until it is required for use. This adaptability allows for an increase in the variety of file formats present in the database. Consequently, this diversity expands the information pool available, enabling data scientists and analysts to selectively prepare and analyze only insights that are relevant to their specific needs. The flexibility of this approach enhances the efficiency of information processing and utilization, catering to diverse analytical requirements without the need for extensive preprocessing.
- Fast Accumulation Rates. The lack of a need to predefine structures simplifies the information collection process, making it fast and efficient. This means that information can be captured in real-time, reducing latency and improving the timeliness of the information. This is particularly advantageous in scenarios where speed is critical, such as in monitoring systems, real-time analytics, or when dealing with large streams of information from sources like social media or IoT devices.
- Data Lake Storage. Utilizing data lake storage offers a scalable solution for managing vast amounts of insights. This method supports massive storage capacities and employs a pay-as-you-use pricing model, which significantly reduces storage costs and facilitates budget flexibility. Moreover, the scalability of lakes enables organizations to easily adjust their storage resources to match their evolving information requirements. This flexibility is crucial for businesses that experience fluctuating information loads, ensuring they have the necessary resources without over-committing financially.
Cons
However, there are some disadvantages:
- Requires expertise. Data science plays a crucial role when dealing with unstructured information, which often lacks a clear format and is tricky to analyze. This specialization is great for analysts but can be a challenge for business users who aren’t as familiar with complex data topics or how to apply insights in a practical way. This gap can lead to misunderstandings and hinder effective collaboration between technical teams and other business departments, ultimately slowing down information-driven decision-making throughout the company. By making this process more accessible, organizations can bridge this divide and enhance overall performance.
- Specialized tools. The manipulation of unstructured information necessitates specialized tools and software, which not only limits the product choices available for data managers but also increases dependency on specific technologies. This can lead to higher costs and a steeper learning curve, ultimately affecting the flexibility and agility of business operations. Furthermore, the reliance on specialized tools can pose challenges in integrating with existing systems, potentially leading to data silos and reduced operational efficiency.
Unstructured Data Tools
Unstructured data analytics tools leverage advanced technologies such as machine learning and natural language processing (NLP) to gather, dissect, and interpret information that lacks a predefined structure. This type of information encompasses a wide range of sources, including emails, reports, social media content, customer support tickets, and more, making it challenging for machines to comprehend without the assistance of unstructured data analytics software.
Depending on your specific objectives and the level of in-depth analysis required, there are various tools that can streamline the process of examining unstructured information.

MongoDB
This instrument utilizes flexible document-oriented structures, enabling efficient processing suitable for various cross-platform applications and services. This approach supports dynamic schema design, promoting rapid development and the ability to handle diverse insight types seamlessly.
DynamoDB
This tool offers high-performance capabilities, achieving single-digit millisecond responsiveness at any scale. It features comprehensive built-in security, in-memory caching, and robust backup and restore options, making it ideal for managing web-scale applications.
Hadoop
This solution makes it easier to handle massive datasets by spreading the work across clusters of computers with a simple programming approach. It’s built to expand effortlessly from a single server to thousands of machines, each providing its own computing power and storage, all without needing rigid formatting rules.
Azure
Microsoft’s Azure offers a dynamic and scalable cloud computing platform that lets you create, test, deploy, and manage applications and services across a global network of data centers. With support for numerous programming languages, frameworks, and tools, Azure empowers developers to craft innovative applications efficiently.
Use Cases for Unstructured Data
The following cases illustrate how leveraging unstructured data can provide significant competitive advantages by enabling more informed decision-making and improving customer interactions:
- Data mining. Data mining in the context of unstructured information aims to extract meaningful insights that are not readily apparent. Businesses utilize mining techniques to sift through vast amounts of unstructured information such as customer reviews, social media posts, and video content. This allows companies to understand consumer behavior, gauge product sentiment, and identify purchasing patterns. The insights gained enable businesses to tailor their offerings better to meet the needs and preferences of their customers.
- Predictive data analytics. Predictive analytics turns raw, unstructured data into a crystal ball for forecasting future trends and events. By analyzing text from customer interactions, transaction records, and social media activity, this powerful tool allows businesses to peer into the future. Companies can predict major market changes and customer behavior patterns, enabling them to tailor their strategies proactively. This advanced insight is invaluable for optimizing resource distribution, fine-tuning marketing efforts, and enhancing strategic planning. The result? Businesses can dodge risks and seize emerging opportunities with confidence.
- Chatbots. Chatbots transform customer service by skillfully managing unstructured information. They swiftly process and comprehend incoming text, accurately identifying the nature of customer inquiries. This smart technology ensures that questions are immediately directed to the right places for fast and accurate responses, significantly boosting customer satisfaction. By automating these processes, chatbots not only quicken response times but also lighten the load on human agents, offering a scalable way to handle a high volume of queries efficiently.
Related articles:
- Top 10 Data Warehouse Software Tools for Your Business
- How to Master an Enterprise Data Warehouse: a Complete Guide
- Predictive Analytics in Retail: Boosting ROI and Transforming Customer Experience
- Best Tech Stack for Optical Character Recognition Automation
- Best programming languages for AI and machine learning
What Is the Difference Between Structured and Unstructured Data?
Data collection and analysis involve both structured and unstructured data types, each unique in how they can be utilized. Structured information is neatly organized, making it perfect for fitting into tables. It commonly includes easily categorized information like numbers, short texts, and dates—think of a neatly arranged spreadsheet.
Unstructured data, however, doesn’t conform to the traditional table format because of its nature or size. Think of audio and video files or voluminous text documents that resist simple categorization.
Interestingly, even information that appears to be structured, like numbers or text, can be unstructured if it doesn’t fit efficiently into a table. Take sensor data as an example: it continuously streams numbers, but organizing these into a basic table of timestamps and sensor values is often impractical.
Both structured and unstructured data are indispensable in analytics, each offering unique insights and challenges.
Key Differences: Structured Data vs. Unstructured Data
Structured information is organized in a tabular format with rows and columns, where each column represents a specific attribute (such as time, location, and name), and each row contains data values associated with those attributes. This organization allows for easy storage, processing, and analysis in relational databases and is particularly suited for queries that require precise computations and quick lookups.
On the other hand, unstructured information does not adhere to any predefined schema or organization. It includes formats like text, images, video, and audio, where the content does not fit neatly into rows and columns. This type of information is more complex to process and analyze as it requires advanced techniques such as natural language processing, image recognition, or deep learning to extract useful information.
Here are some more distinctions between structured and unstructured data in machine learning.
Data Format
Structured information sticks to a clear and specific format, guided by a predefined model or schema, making it easy to organize and understand. Conversely, unstructured information plays by its own rules, lacking a consistent format or schema. Imagine having all meeting recordings in a random mix of formats instead of just MP3, or system events scattered across various locations rather than a single, specified storage space. This lack of structure can make it harder to manage and access information effectively.
Data Storage
Different types of data storage can store unstructured and structured data. The choice of storage depends on the characteristics of the information, the purpose of collecting it, and the type of analysis needed.
Structured insights are commonly stored in relational databases, spatial databases, and OLAP cubes, while large collections of structured information are often stored in warehouses. File systems, digital asset management (DAM) systems, content management systems (CMS), and version control systems often contain unstructured information, which is typically stored in data lakes.
Some storage systems used for structured information can also store unstructured one and vice versa.
Data Analysis
When data is structured, it is organized clearly and predictably, making it easier to manage. Structured information can be easily searched, analyzed, and modified using programming logic, and automating tasks related to structured information is efficient and straightforward.
On the other hand, unstructured data lacks predefined organization, posing a challenge in search and categorization. The analysis of unstructured data often requires the use of complex algorithms to preprocess and manipulate the information for meaningful insights, sparking your intrigue and curiosity in data analysis.
Technologies: Structured Data vs. Unstructured Data
Understanding and utilizing information depends heavily on its type—whether it’s structured or unstructured.

Structured data is neatly organized and follows specific rules, making it easier to manage using traditional analysis tools:
- In-Database Analytics. Most structured storage systems support robust in-database analytics.
- SQL Queries. SQL is the backbone of structured data analysis and allows you to extract and manipulate information efficiently.
- Advanced Tools. Beyond SQL, structured information can also be explored through data visualization, statistical modeling, and even machine learning to uncover deeper insights.
In contrast, unstructured information is more chaotic and lacks a predefined format, necessitating more sophisticated tools:
- AI and Machine Learning. These technologies are crucial for making sense of unstructured data, as they help in structuring and analyzing the information.
- Programming Libraries. Various programming languages offer libraries specifically designed to handle and analyze unstructured information.
- Preprocessing Requirement. Before analysis, unstructured data often requires preprocessing to transform it into a more analyzable form.
When to Use: Structured Data vs. Unstructured Data
Structured data and unstructured data play vital roles across various industries, organizations, and applications in the digital world. These forms of insights are extensively collected and utilized for tasks such as analysis, decision-making, predictions, generative applications, and more. While structured data is commonly associated with quantitative information and unstructured data with qualitative information, this distinction may not hold true in some cases.
Structured Data
Structured data is precious when working with specific, numerical insights. This type is commonly found in financial transactions, sales and marketing information, and scientific models. Structured data is also essential for managing records that contain short text entries, numbers, and categorized fields. This approach includes maintaining human resources records, organizing inventory details, and managing housing information.
Unstructured Data
When handling unstructured data, its importance shines when you need to keep a record but can’t fit the info neatly into a traditional, structured format. Think about all the diverse types of data that fall into this category; video surveillance footage, a myriad of company documents, and dynamic social media posts.
Moreover, unstructured data is crucial when structured one isn’t practical. Examples include the sprawling information from Internet of Things (IoT) sensors, the detailed logs from computer systems, and the real-time flow of chat transcripts. This type of data captures the complexity and richness of information in ways that structured data simply can’t.
Semi-structured Data
Semi-structured format bridges the gap between structured and unstructured data types. Imagine a video library where each clip is tagged with key details like the date, location, and topic. These tags, known as metadata, categorize the videos as semi-structured data. This unique mix of structured and unstructured elements not only enriches the data but also simplifies and accelerates analysis, offering the best of both worlds.
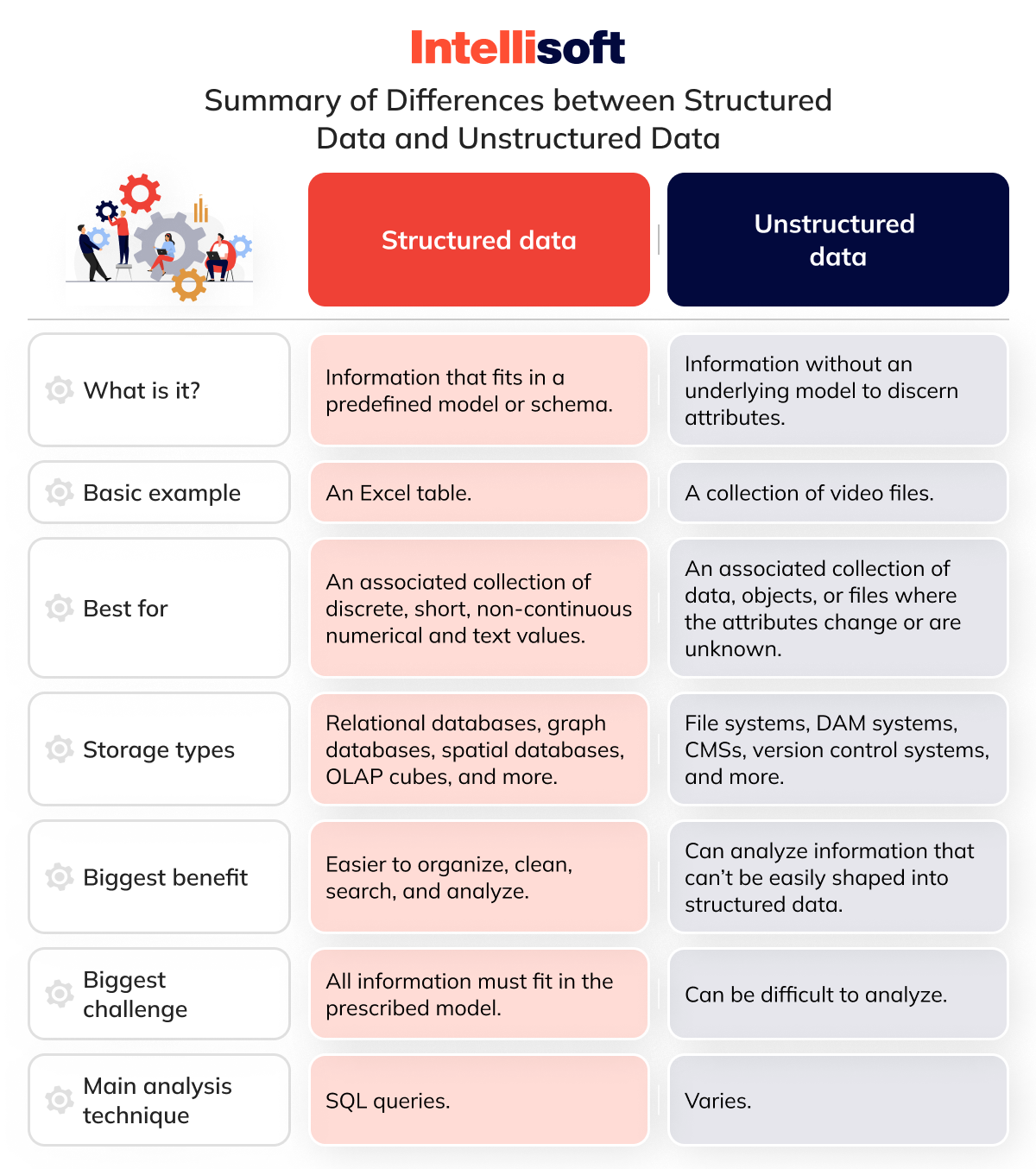
Summary of Differences: Structured Data vs. Unstructured Data
Let’s summarize the difference between structured and unstructured data in the table below.
What Is Semi-structured Data?
Semi-structured data is a type of information that is only partially structured. This approach contains certain markers that can identify different elements and establish hierarchies, but it does not adhere to the strict tabular structure found in relational databases. It is considered “self-describing,” as it contains tags or markers that provide information about the structure and meaning of the information. Examples of semi-structured formats include markup languages like XML and JSON.
JSON, in particular, is a popular semi-structured model used by modern databases such as MongoDB and Couchbase. Many Big Data tools and solutions leverage semi-structured data due to its ease of processing compared to unstructured data.
Despite its advantages, semi-structured data is not a perfect solution. In today’s competitive business environment, organizations must effectively utilize all available information sources to gain insights and derive maximum value from the information.
Why You Should Manage Your Unstructured Data
Nearly every business backs up its information. Yet, as business-related insights balloon each year, storage becomes a daunting task. A significant portion of this information, often referred to as “cool” data (that isn’t accessed for at least 30 days), takes up precious space on costly hard drives, escalating storage expenses.
The real challenge kicks in with unstructured information that doesn’t fit neatly into traditional databases. It’s tough to organize and even harder to analyze because standard tools like XML, key-value, and JSON databases aren’t up to the task. Typically, businesses must rely on secondary systems to handle the heavy lifting of extracting, analyzing, and processing this information. This not only involves additional storage costs, but also isn’t economically efficient.
Some companies, overwhelmed by the complexity, simply increase their primary storage capacity. This approach, however, is fraught with problems:
- Capacity Crunch. Unstructured data can quickly fill up primary storage, leaving no room for anything else. And since primary storage often relies on pricey flash drives, the costs can skyrocket.
- Frequent Upgrades. Every three to five years, businesses face the need to update their storage infrastructure. This approach includes all the cumbersome cool, unstructured insights, not to mention the costs of migration and maintaining secondary backups.
- Legal Compliance. Global data governance laws compel firms to maintain a clear inventory of their unstructured information, ensuring it does not contain sensitive information like personally identifiable information.
However, it’s not all doom and gloom. Efficient management of unstructured data can optimize performance and cut costs. Solutions such as cloud services, tape, or secondary storage offer more streamlined, cost-effective ways to handle the complexities of unstructured information.
Conclusion
Let’s clear the air. There isn’t really a battle between structured unstructured and semi structured data. Both are incredibly valuable for businesses of all sizes and sectors. While the type of information might guide our choice of relevant source, we often don’t have to pick one over the other. Instead, we explore software solutions that can manage both types effectively.
In earlier days, companies often ignored unstructured information because there was no efficient way to analyze it. They focused on structured insights, which was simpler to quantify. Today, however, we have artificial intelligence and machine learning that make it possible to analyze complex unstructured data. Take Google, for example, which has revolutionized image recognition with AI algorithms capable of identifying the contents of photos.
The difference between structured and unstructured data isn’t as stark as it used to be. Most information today is semi-structured. Even a simple photograph, which seems unstructured, contains elements such as size, resolution, and the date it was taken, which can be systematically organized in a relational database. Understanding the characteristics and differences between these types can help you make informed decisions about investing in technology to leverage the advantages of unstructured information. Ideally, embracing both types of information can significantly enhance your business intelligence and overall effectiveness.
At IntelliSoft, we specialize in turning complex data environments into streamlined insights. Our expertise spans software, web, and cloud development, making us your ideal partners for handling both structured and unstructured data. As dedicated partners in data analytics and management, we’re equipped to provide tailored enterprise data management solutions. Contact us today to discover the tangible benefits of structured and clear insights that are custom-made for your needs!