Dave is a committed technician working aboard a busy vessel that traverses expansive and often isolated ocean routes. His core duties involve carefully reporting on aging vessel parts that need immediate replacement and making sure the stock inventory is always precise and up-to-date.
Given the critical nature of his tasks, any delays or errors in reporting could cause serious operational issues or even endanger the safety of the crew. However, Dave grapples with a challenge that’s all too common in his line of work: the unpredictable and often unreliable Internet connection at sea. Multiple times a day, as the vessel navigates through areas with poor or no connectivity, Dave struggles to access the digital tools he needs, underscoring the necessity of mobile synchronization for him to carry out his responsibilities smoothly and without interruption.
In this article, we’ll explore the complexities of offline data synchronization in logistics apps, focusing on how this vital feature ensures uninterrupted operations even in the most difficult conditions. We’ll delve into the sophisticated technologies required to develop such a dependable solution and share valuable insights from the IntelliSoft development team.
Table of Contents
What is the Offline First Mobile App?
Imagine that you are uploading the new Story to your Instagram profile. And then, you found out there is no Internet connection. What will happen next? The app saves your picture to cache so that it appears in the Story section once your device connects to the Internet.
This functionality demonstrates the Offline First software engineering principle, which allows accessing functions of a mobile app while the Internet connection is poor or non-existent.
The offline mode is beneficial for social media apps. But, there are some cases, in particular in the logistics and warehousing industries, where data synchronization in mobile computing is crucial for the overall work processes and successful work of employees.
Benefits of Offline Sync for Mobile Applications
Offline mobile synchronization allows mobile apps to work without an internet connection. In this way, the app stores data locally on the device and synchronizes the data with a remote server once the connection is restored.
Offline sync can improve your mobile app’s user experience and performance. By using a local database for offline sync, you get further offline sync benefits:
- Better app responsiveness
- Better app reliability when there’s bad network connectivity
- Faster access to data
- Lower network traffic and bandwidth consumption
- Improved handling of network errors
Mobile app offline data synchronization can also improve the reliability and security of your data, as you can encrypt it locally and back it up regularly. Offline sync can also enable new features and scenarios, such as offline editing, offline search, offline analytics, and offline-first design.
Offline Data Synchronization for Mobile and Web: Key Usages
As we said, offline functionality might be critical for the user experience of mobile and web applications. Now, let’s look at examples of offline data synchronization in logistics applications industry that include:
On-demand Delivery Apps
Think about a delivery guy delivering an on-demand order from a restaurant. He’s on the way to the customer’s location, and suddenly the courier app on his mobile device loses its connection with the Internet. The guy doesn’t know how to reach the point of destination, nor can he inform the customer that he’ll be late because of the traffic jam. In this case, offline features might be helpful for a built-in offline map that shows the direction saved in the cache and allows sending order updates automatically once the courier device re-establish the proper Internet connection.
Warehouse Inventory Management Systems
Imagine a warehouse manager who’s checking inventory supply using a barcode scanner. Once he scans all the new inventory, the latest data should be automatically uploaded to the central database. We just described the scenario from the perfect world. A bad connection in the warehouse or the absence of an internet connection is a common thing that makes online barcode scanning impossible. On the other hand, implementing offline functionality to the inventory application and sending scanned data to the central database once the Internet connection is established will make mobile scanning solutions run smoothly and increase workers’ productivity.
Fleet Management Apps
Think about a logistics manager who is responsible for order delivery between warehouses or to the end-users. One is using a fleet management application that requires offline functionality to make the work done. Why? Because for effective last-mile delivery, the logistics manager must know when the vehicle driver will reach the point of the destination and the number of orders already delivered and how much free space is inside the vehicle so that the driver can arrange extra delivery.
To face the last mile problem, known as the most vital aspect of the entire delivery process, you can enable offline support, which will help employees to enter data anywhere and anytime they need into the logistics management app with or without Internet access.
Now that you know the importance of offline support let’s look at methods to implement this feature in your project.
Related readings:
- Barcode Scanning for Ultimate Inventory Digitalization
- Top 7 Smart Warehouse Technologies for Ultimate Warehouse Optimization
- How To Develop An App For Logistics Business And Make It Successful
Offline Sync Examples of Mobile Apps
To understand how offline data synchronization for mobile and web apps can be applied in practice, let’s look at examples of products that use offline sync for mobile apps.
- Evernote, a popular app for note-taking, allows users to create, edit, and access notes offline and sync adits with the cloud when the user goes online.
- Spotify, a music streaming app, enables users to download and play songs offline and sync them with their account after restoring the internet connection.
- Google Maps, a navigation app, allows users to download and view maps offline via a local database for offline sync and, later, sync them with their location and preferences.
All mentioned offline sync examples of mobile apps illustrate how mobile app offline data synchronization can improve functionality and usability for users.
What is Data Synchronization: Key Approaches
Before digging into more details of offline functionality, let’s clarify what components are included in this process.
First, a client application must enable users to use or change information.
Second, a cloud or on-premise server must include databases with information users interact with.
One example is a warehouse application that allows users to change the number of parts left. Once the user inputs the new data, the application sends those changes to the database located on the server side and makes changes according to the user input. Still, what will happen when there is no Internet connection? Let’s check this out.
Local Caching
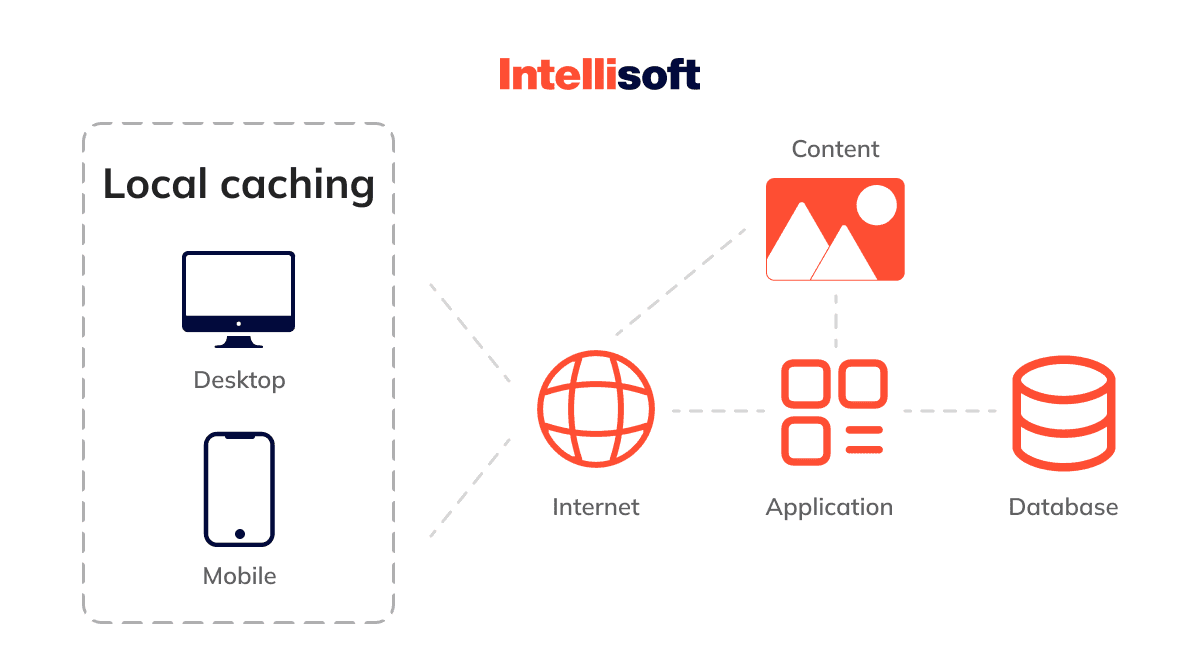
Local caching is for offline functionality and features. Local caching enables the application to combine multiple write operations on the same file region into one write operation across the network.
To refresh the data on the cache, you might apply the following strategies:
- Local first. The app is sent back from the local cache and doesn’t go to the network for a specific period. We apply this approach for cases with no risk of showing cached data.
- Network first. The software obtains info from the local cache. Connection to the server is absent in this case.
- Hybrid approach. The app sends back the data from the local cache before fetching data from a service. In this case, the application can wait for a notification from the server, or when the app doesn’t receive any notifications, it will poll the service in the background to refresh the data to cache it locally.
Local Queuing
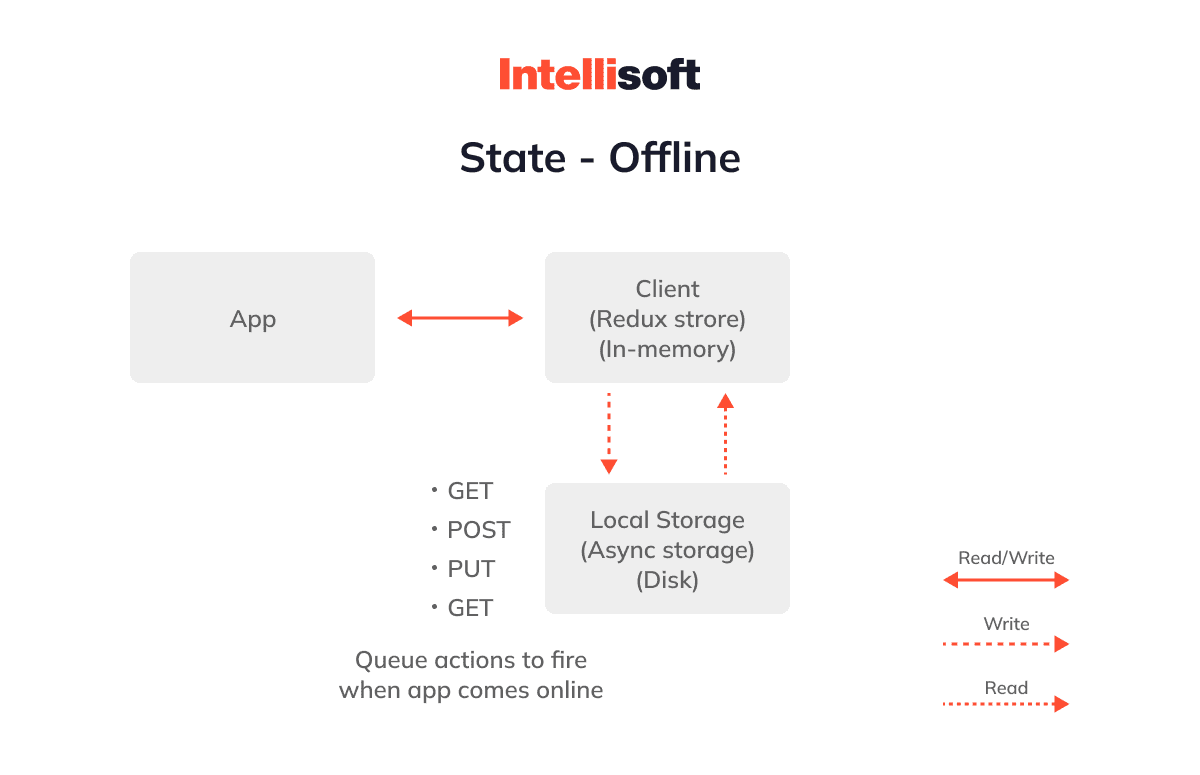
Local queuing is leveraged to make some app features work offline. When the application loses its connection to the network, the queue manager’s server requests are queued locally for later processing. The queue manager will also notify the user that the server has successfully processed queued operations.
In case you are considering local queuing for your app’s offline functionality, think about providing users with the following information:
- Notifications about the queued operations
- The progress and the actual status of the queue
- Availability to cancel a process while it is still in the queue
- The outcome of the data input (success or fail)
Synchronization Data
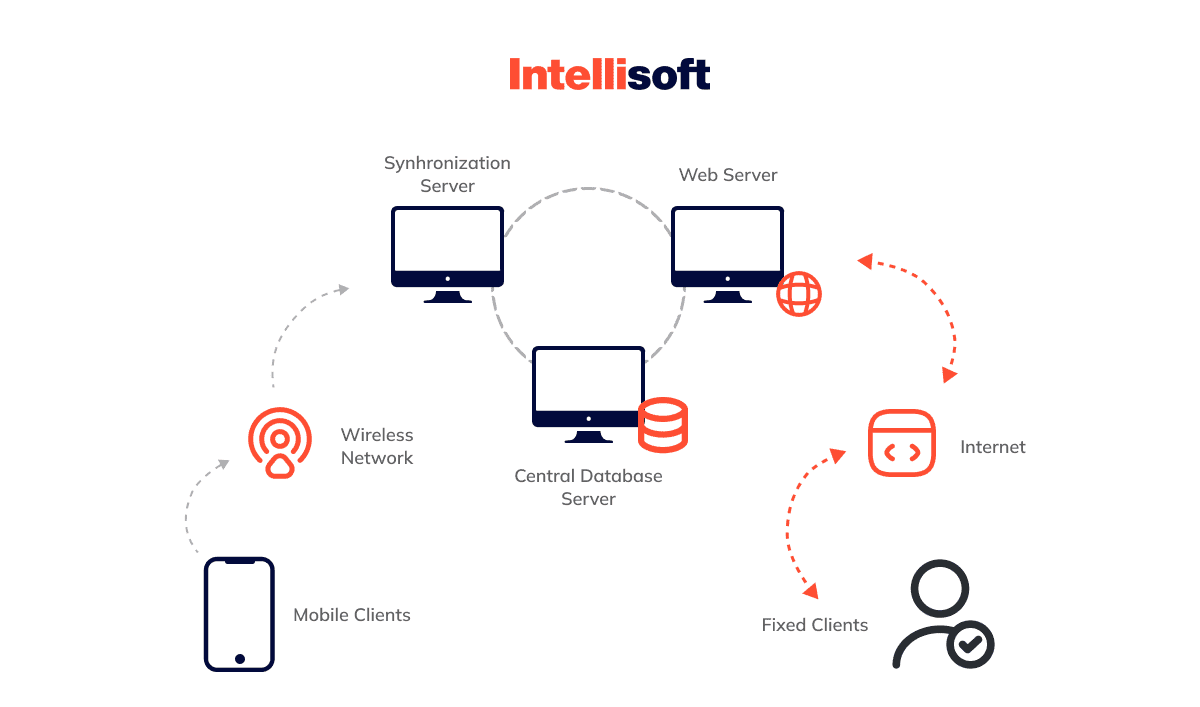
Mobile data synchronization is another technique for sending data from the device to the server. This approach leverages both local caching and local queuing. The data synchronization method is proven for data exchange between two or more devices to maintain consistency within systems.
In case you want to leverage data synchronization for your project to work offline, you can choose between the following types of synchronization:
- Mobile Data up-to-date. The mobile application applies to or reconstructs the server’s current state using local caching or by querying the server for the latest changes.
- Server Data up-to-date. The most common way is to use local queues with the changes on both the server and the app.
Despite being the most convenient way, data synchronization techniques for mobile devices are not the silver bullet since network loss often leads to data concurrency conflicts. At that point, the developer’s responsible for ” merging” changes that occurred on the server and the app. To merge the data and solve conflicts, the developer can either:
- Keep the device version
- Keep the server version
- Keep both versions
Data Replication in Databases

One example is when the application should provide users with access to data relevant to their tasks so that everyone can work without interfering with others. Developers leverage this method to improve data availability and increase bandwidth. The typical case includes one server and a high load on it., which may cause the application to turn down because the operation memory is full or downtime is too long.
Replication means that one or more copies of the central database are stored on two different servers, synchronized with each other. One server is a “master” node that receives all the queries for data recording, while the other server is a “replica” node that takes over traffic loads. If we want to make some changes, we call the first “master” server; the server receives all the necessary changes and sends all renewed data to all “replica” servers. If the user needs to read data, one can read it from all the available servers.
If something happens to the “master” server, the “replica” server assumes its functions so that other “replica” servers will connect to the new “master” server. Thus, despite any unpredictable circumstances, the system will still work.
Depending on the business features, the application may require full replication, i.e., the whole database is stored at every site, or partial replication – when some frequently used database fragments are replicated and others – don’t.
Apart from offline support, businesses integrate data publication into their apps for disaster recovery, backup, and high data availability.
Does data replication functionality sound similar to data synchronization? Yep, it does. But there are some differences between those two methods.
Data Replication in Databases vs. Data Sync: Any Differences?
As we said, data replication includes storing the same information in different locations so that all the data is fully mirrored or replicated to another server and stored at least twice. In this way, data becomes more available and accessible to users while staying data loss-proven. Moreover, replication works only in one direction, which means it includes no additional logic nor the possibility of data conflicts.
On the other hand, Data Synchronization refers to a subset of the data (selection) and works in both directions – from the client side to the server and vice versa. Thus, it is known as (bi-directional). Such logic adds a layer of complexity at some point since it can cause conflicts between similar data. At the same time, the developer can select all data synchronization in one direction, making it work in the same way as replication, thus, eliminating possible conflicts.
But the main difference is that this logic works in only one direction – data replication cannot replace synchronization.
IntelliSoft experience with an offline app
When the SpecTec team hired us, they already had offline functionality in their logistics infrastructure – which helps in vessel maintenance. The team developed the application for field workers who served the ship and were responsible for fulfilling assigned tasks (including old parts replacement), writing reports with photo proofs, and keeping actual stock inventory up to date.
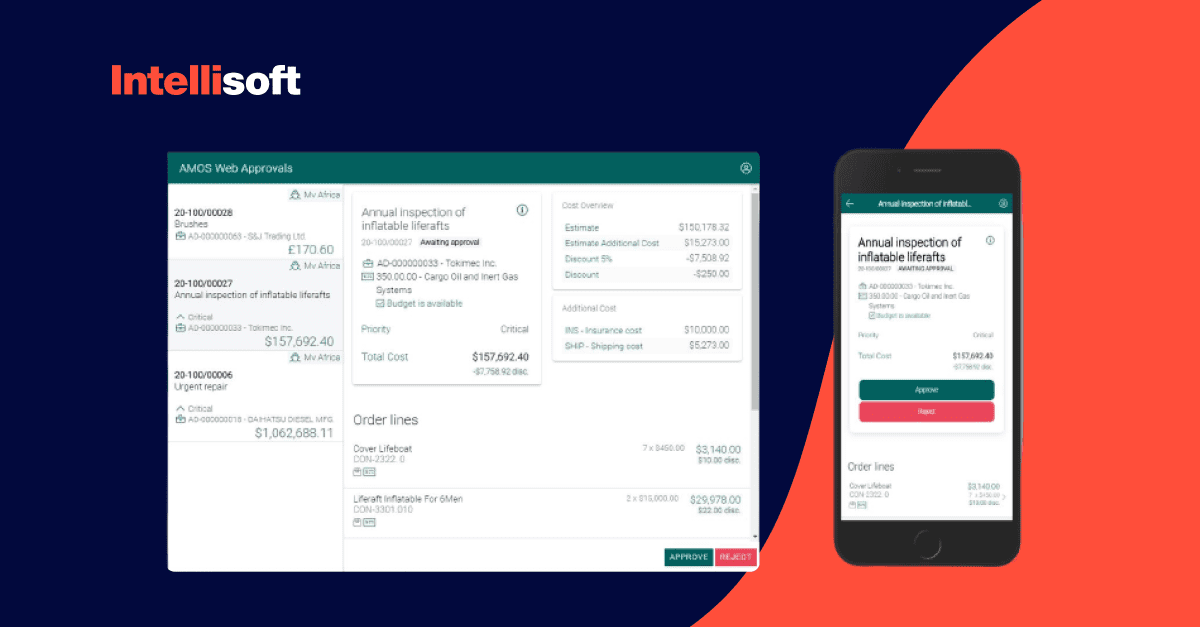
The main issue the clients needed help with was ineffective offline functionality caused by problems with poor performance, the size of entities recorded to the database, the size of the local database, etc. Thus, our main task was to change the approaches used for data synchronization in a mobile application, change the data used for synchronization, and implement other improvements to the system.
Initially, the mobile app used an offline data synchronization method for particular business functionality. But, the client wasn’t satisfied with the time the app synchronizes data updated with the central database. Thus, our task was to optimize the offline functionality performance using data replication and reduce conflicts that frequently arise since many users have input different information into the central database.
To avoid the conflicts that arise during the synchronization, we relied on data replication, i.e., we separated users from making changes in the central database by allowing them to interfere with its copy, saved in the device.
- We made a snapshot of the central database stored on the server for the last time the user was online.
- Created a copy of the database to store it on the device.
- The user can view this database, do searches, etc.
- If the user needs to make any changes to the central database, the app creates those queries and stores them in the local queue in the database changelog.
- Once the user’s device connects to the network, the app sends all the changes to the central service that validates the correctness of those changes.
- In case of wrong data input, the central service marks it as an “error” and sends this info to the user device so that one can see something wrong with the input data.
- If all the imputed data is correct, the system implements all the changes in the central database.
- Now, the system conducts the secondary synchronization data that includes a new database snapshot stored on the device.
For the data replication method, we used Couch DB because this tech stack has an effective data replication mechanism. CouchDB allows making all those operations to the central database in real-time – the app sends all the changes to the central database stored on the server, and all the changes are validated and applied to the central database. Then, the application sends an updated database to the device.
If the user’s device loses the connection with the network, this process takes longer to fulfill.
This functionality took us 200+ hours to implement. To receive an estimated cost for offline feature implementation to your project, fill in the contact form, or use our Dev Team Cost Calculator.
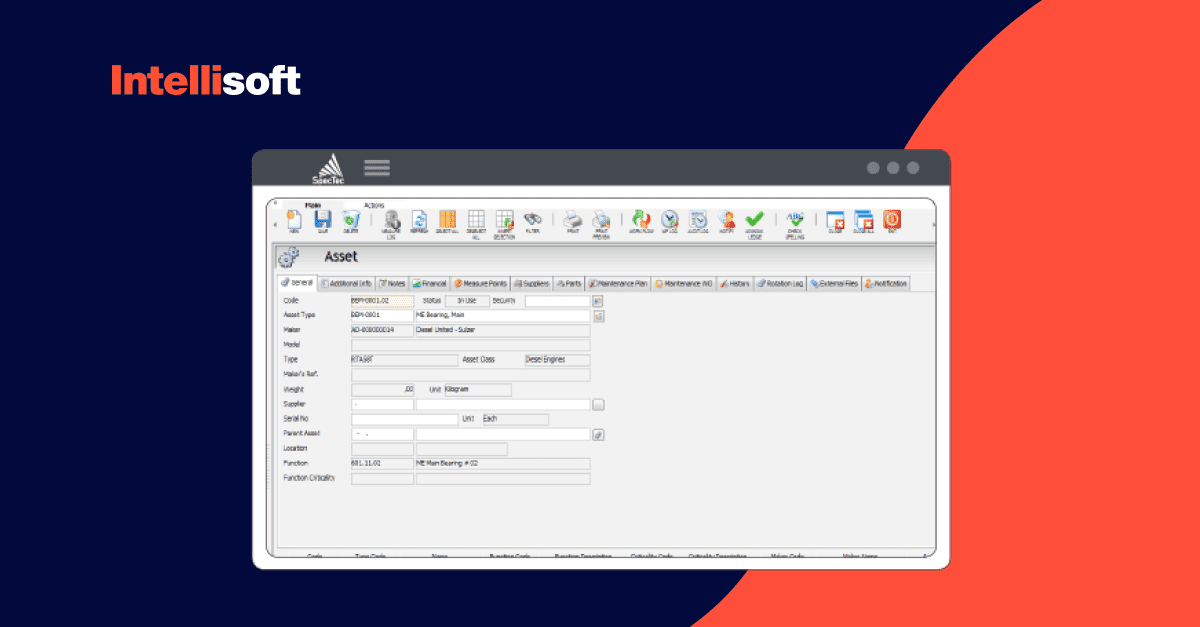
The IntelliSoft team also implemented the “virtual data” approach to achieve the client’s goals. We uploaded the snapshot of the local database to the device and applied all the changes in the queue.
One example of when this can work well is when the user changes the item name in the central database. One requests changes, which will be stored in the queue until the devices connect to the network.
If the user stays offline, other users can’t see one’s changed data because if the user remains offline, the server can’t receive those requests for changing the item’s name. If other users read data from the local database, one can’t see necessary changes, only the old database version without updates.
Virtual data allows users to receive all the data about a particular item and then apply the request from the queue for the item name change. All these actions happen not on the server but on the device’s operating memory. The user sees all the changes on the device as if they were made on the main database. Despite requests are still in the queue.
If the user inputs the data, which the main server validates as an “error,” the user has one more try to input the correct information to the central database a little later.
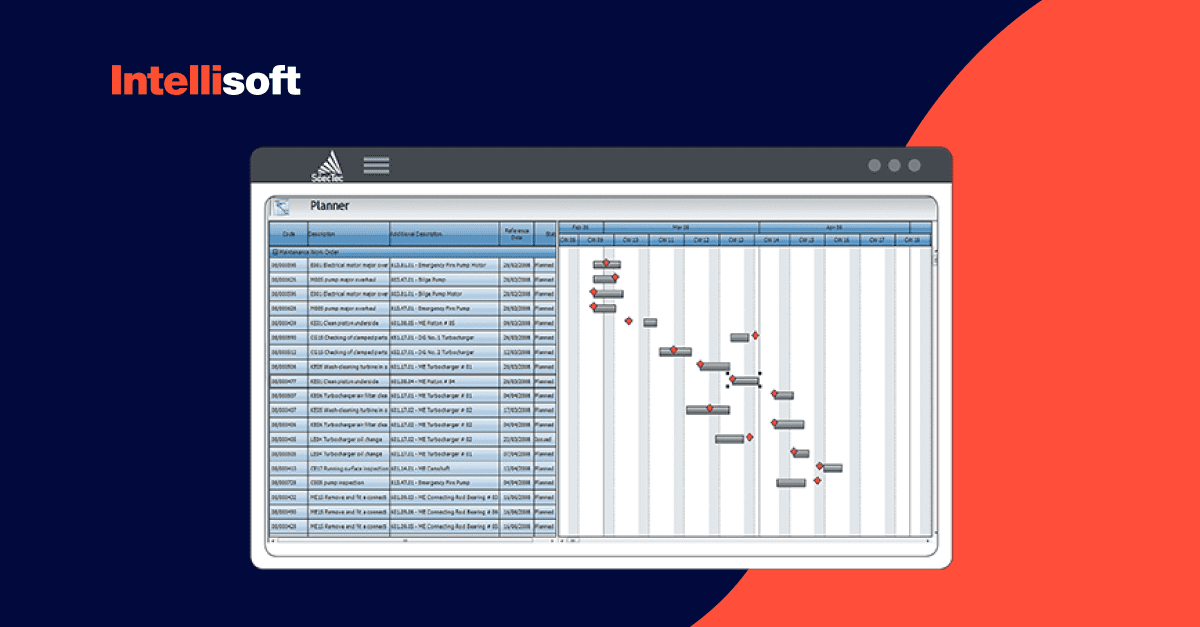
One of the challenges of this project the IntelliSoft team dealt with was implementing a particular business logic twice – on the server and on the client side.
One example is the Counter feature, which tracks the equipment usage built into the system. The user input manually how much time the vessel uses the equipment. If the amount of usage is more than stated in the usage guidance, the equipment requires maintenance.
The system automatically creates a maintenance work order for technicians, which must be implemented on the server, client, and back end and include the same data in the same format. For this function, we also used the concept of virtual data by making those virtual data follow the same rules on the back-end.
We also have issues with central database synchronization. The application leverages an SQL server, a relational database. At the same time, the primary synchronization logic was built on a non-relational NoSQL database, CouchDB. Thus, we needed to synchronize SQL and NoSQL databases.
Another issue we dealt with was the long waiting time for offline business logic. Even if the user was online, the device received all the data modifications with the delay caused by the long launching period of the task scheduler responsible for SQL and NoSQL database synchronization.
We implemented another logic to the data sync – when the user modified the database, the app saved those changes on the SQL database. Changes went to the Couch DB; then, replication on the Couch DB sent the data to the user device.
After we improved the synchronization method, it worked almost in real-time, and downtime for synchronization was minimized.
The IntelliSoft Tips on Offline Mobile App Development
How to implement offline data synchronization in mobile app? In the next section, you’ll find some tips that might help you to implement the offline functionality to your project and avoid some main challenges.
Re-consider use cases
First, think twice before adding an offline mode since the online method is much simpler to implement. If your project can work without offline mode and your users are happy about that, do not add offline mode.
If your project needs offline support for its core business functionality, you’ll need a clear idea of what functions the user can interact with and what kind of data it will interact with. Use cases will help your development team separate complicated business functions from simpler ones.
You’ll also need a clear logic for offline functionality, explained in the technical documentation that tells what the user can and can’t do. We advise you to restrict your user as much as possible at this point to minimize the pool of tasks and unnecessary complications of the system.
The tech documentation must also include details about how to store data, manage transactions without the network connection when to sync the device with the server, and approaches to keeping the offline data secure.
Have solutions for conflicting data
Information conflicts are a common problem in data synchronization for offline functionality. Those conflicts could arise for many reasons, but you should inform the user about the next steps when conflict is unavoidable. Here are some common causes of offline data synchronization conflicts and how to handle them:
- Order of actions. The software must replicate the actions executed offline on the server in the same order the user did on the device. In this way, developers can achieve action coherence. On the other hand, some actions registered offline can invalidate future events. This situation can occur when the user places an order for an item that is out of stock. In this case, all future events with this order will fail.
- Failure feedback. Your software must send feedback to the user’s device after the data sync. In case the sync of events fails because of server validation, the user must be informed about the error so that one can know that an error occurred and take further actions.
- Images sync. Such files, such as audio, video, and images, can cause problems during synchronization since all those files can be significant in size, take lots of space, and make the synchronization longer.
Identify your pattern
For offline functionality, several common patterns define what users can do with the device and server information. Knowing those patterns will help you with the use cases and the logic required to resolve data conflicts. Those patterns are:
- Read-only Data. The most simple pattern is the user can read the data on the app when there is no network connection – the user downloads the data from the back-end and updates it to the local database. If you need to sync a large amount of data, the app should analyze that data on the device first and update only new or changed information.
- Read/Write Data (Last Write Wins). If only one user changes the database offline, this is an excellent pattern to apply. After the user changes the data on the local database using the read-only data pattern, the app tracks all the local changes to be synchronized later to the database. But if several users change the same data simultaneously, synchronized with the server, the last change wins. This pattern may cause data loss. Thus, consider the following pattern if your app includes several users who will operate offline.
- Read/Write Data With Conflict Detection. This pattern suits projects with several active users who operate offline. Since it is a more complicated scenario than the two previous patterns, it requires conflict detection and resolution techniques. The solution might include tracking changes and detecting conflicting changes upon synchronization. But the conflict detection process is highly personalized for every system and mainly depends on the used data type and the feature use case.
Developing an offline app with IntelliSoft
There are many scenarios and use cases when offline support in mobile apps is critical for essential business functions. The need for offline synchronization also concerns mobile and web applications for the Logistics industry, where the connection to the network might appear several times a day for a short time.
Despite the usage, the IntelliSoft team is here for your business success. Hire us to improve the performance of the existing offline features or request an offline app development – we’ll do our best to fulfill your requirements.