Organizations are constantly bombarded with information from IoT devices, social media, transactional systems, or customer interactions. The real challenge isn’t just gathering this vast amount of information, but converting it into valuable insights while ensuring its integrity and security.
This is where a data pipeline becomes essential. It guarantees a seamless and efficient flow from the source to storage and analysis platforms by automating insight collection, transformation, and loading. When properly designed, pipelines provide organizations with precise and trustworthy information, enhancing operational efficiency and supporting more thoughtful decision-making.
How to build data pipeline? Let’s take a closer look at pipeline architecture, explore best practices, and understand how they can be effectively implemented to optimize your data strategy. Be forearmed by the quality knowledge provided by IntelliSoft!
Table of Contents
What Is a Data Pipeline
Let’s explore the data pipeline meaning. It functions like a bridge that links different systems, enabling information to travel smoothly from one point to another. It’s a collection of tools and processes designed to transfer insights from its source—where it’s stored and handled in a specific way—to a new system that can be stored and managed differently. The true power of pipelines lies in their ability to automatically pull in information from various sources and then transform and consolidate it into a high-performance storage environment.
Imagine you’re gathering different information about how people interact with your brand—their location, the devices they use, session recordings, purchase history, customer service interactions, feedback, and more. All these insights are then organized into a single location, like a warehouse, where you can build detailed profiles for each customer.
This consolidated information allows everyone who needs it—making strategic decisions, developing analytical tools, or managing daily operations—to access it quickly and easily. Analysts, BI developers, chief product officers, marketers, and specialists depend on these unified insights to do their jobs effectively.
Data engineers are the professionals responsible for constructing and maintaining this infrastructure, ensuring that information flows smoothly and is strategically utilized.
Types of Data Pipelines
Pipelines are divided into two main types:
- Batch processing. Batch processing is like setting your information tasks on a timer and running them at specific intervals. It’s perfect for situations where you don’t need instant results, allowing you to efficiently manage and process large amounts of insights without the pressure of real-time demands.
- Streaming data. Streaming pipelines work in the fast lane, handling information as it flows in real-time. This approach is essential for applications that require immediate insights and quick responses, ensuring you’re always acting on the most current insights available.
When Do You Need a Data Pipeline?
Establishing a reliable consolidation and management infrastructure is crucial for organizations looking to drive their analytical tools and maintain smooth daily operations. A data pipeline becomes indispensable if you want to leverage information in diverse ways. It is particularly useful when integrating data for tasks such as processing transaction data and analyzing quarterly sales trends.
To carry out such analysis, it’s essential to pull information from various sources—whether a transaction system, CRM, or website analytics tool—consolidate it in a centralized storage location and prepare it for analysis. A well-designed cloud data pipeline streamlines this process, efficiently managing the flow from information origin to its final destination, even when handling large volumes of information.
As your use cases expand, so do the complexities in how information is stored, processed, transmitted, and used, making a strong pipeline all the more critical.
Data Pipeline Components
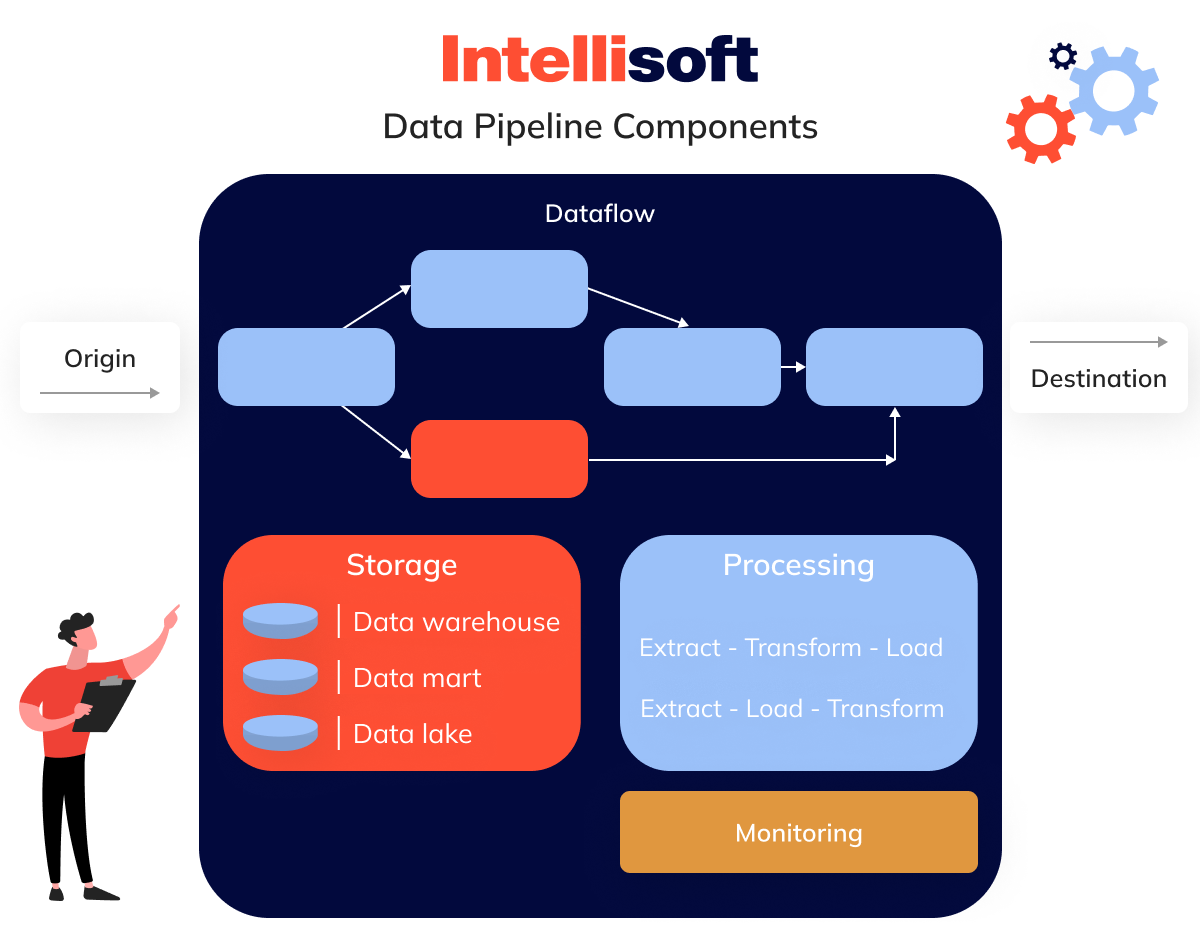
It’s helpful to break down its core components to fully understand how a pipeline functions. Senior research analyst David Wells from the Eckerson Group identifies eight essential elements that typically comprise a pipeline data. Here’s a summary:
- Origin. This is where data enters the pipeline. Origins can be diverse, including transaction processing systems, IoT devices, social media platforms, APIs, or public datasets. Storage systems such as warehouses, lakes, or lakehouses also act as origins, feeding information into the pipeline.
- Destination. The endpoint is where information is ultimately transferred. Depending on the objective, this could be a visualization tool, an analytical data pipeline platform, or another storage system such as a data lake or warehouse. We’ll explore different storage types later on.
- Dataflow. This component refers to the path information travels from origin to destination. Along the way, insights may undergo transformations, pass through various storage systems, and be adapted for its final purpose.
- Storage. These systems store information at different stages of their journey. The choice of storage depends on volume, query frequency, type, and how these insights will be used. For example, an online bookstore’s storage needs would differ significantly from those of a social media platform.
- Processing. This element involves all the actions needed to move information from its source through storage and transformation to its destination. Processing prepares data for the next stage, whether through extraction, replication, or streaming, and there are many possible methods to achieve this.
- Workflow. Think of the workflow as the pipeline’s blueprint. It maps out the sequence of tasks and their dependencies. Understanding terms like jobs, upstream, and downstream is crucial. A job is a specific task performed on the information. “Upstream” refers to where the information originates, while “downstream” indicates its destination. As water flows downstream, data moves through the pipeline, with upstream tasks needing completion before downstream tasks can start.
- Monitoring. Data pipeline monitoring ensures everything works smoothly. It checks the pipeline’s capacity to handle increasing information loads, maintains accuracy and consistency, and prevents information loss.
Data Pipeline vs ETL
There’s often some confusion between what constitutes a pipeline and what we call ETL. So, let’s start by clearing that up. In simple terms, ETL is just a specific type of data pipeline that involves three key steps:
- Extract. This is all about gathering or ingesting information from various, often different, source systems.
- Transform. At this stage, the information is moved to a temporary storage area, commonly known as a staging area. Here, insights are transformed to match agreed-upon formats, preparing them for future use, such as analysis.
- Load. Finally, the reformatted information is loaded into its final storage destination.
This approach is common but not the only way to move letters and figures around. For instance, not every pipeline includes a transformation step. You might not need to transform the data if the source and target systems use the same data format. We’ll dive into ETL vs data pipeline in more detail later on.
What is Data Pipeline Architecture?
A data pipeline architecture can be considered a roadmap, guiding how information moves from its source to where it’s ultimately needed. Picture it as the journey your information embarks on—starting from its origin, passing through various transformations, and finally reaching a format ready for use.
Typically, this journey involves three main steps: extraction (pulling information from the source), transformation (reorganizing and refining it), and loading (storing it for future access). This data pipeline process is often called an ETL or ELT pipeline.
But, in reality, most pipelines aren’t just a simple path from point A to point B. Instead, they’re more like a complex web of interconnected processes. Information might be pulled from multiple sources, reshaped, and merged at different stages before arriving at its final destination. It’s a dynamic, multi-step journey where each stage is crucial for delivering accurate and valuable insights.
What Is the Importance of a Data Pipeline Architecture?
Building a robust pipeline is crucial for effectively managing big data, especially when faced with the challenges posed by the five Vs: Volume, Velocity, Variety, Veracity, and Value. While these factors can present significant hurdles, a well-designed pipeline allows you to tackle them confidently.
Here’s how a pipeline can enhance your business:
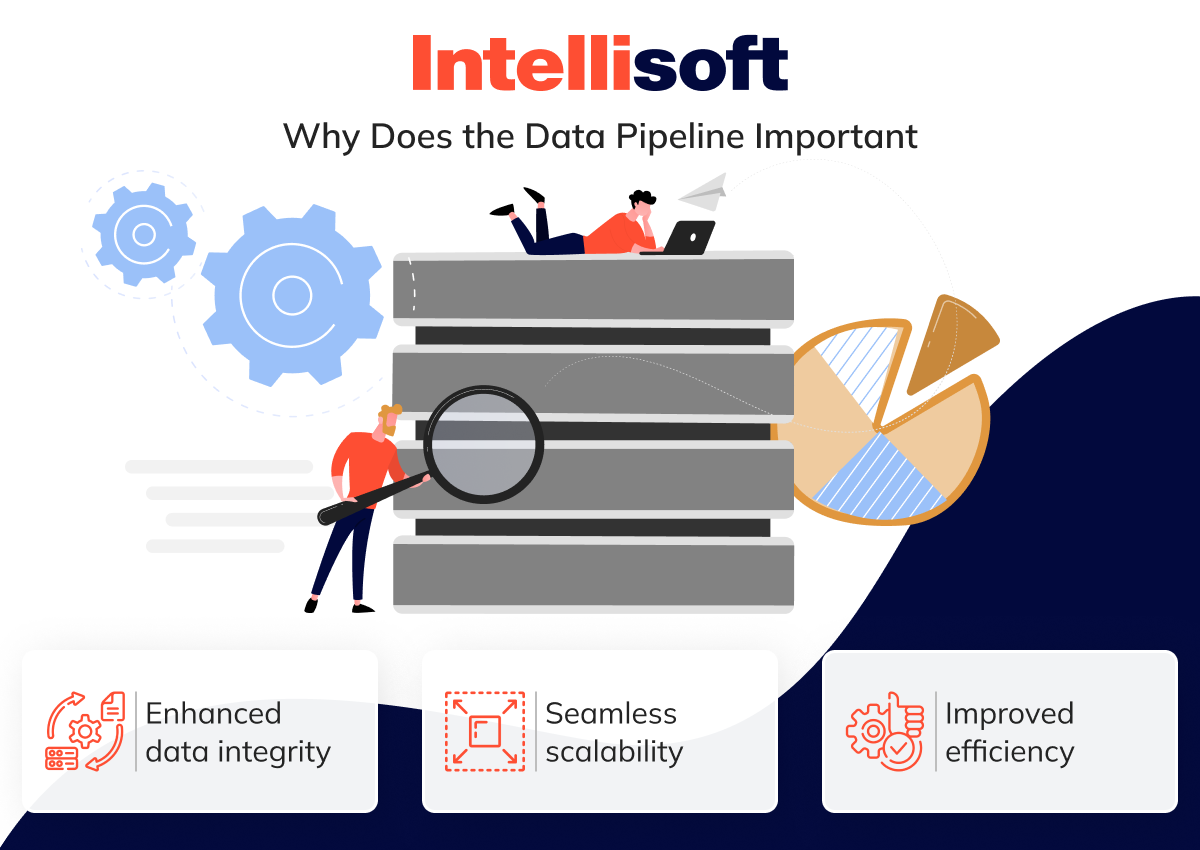
- Enhanced data integrity. A pipeline automates cleansing, validation, and standardization processes, ensuring your information remains clean, consistent, and accurate. This reduces the likelihood of errors and helps maintain data integrity by quickly identifying and resolving any issues.
- Seamless scalability. As insight volumes increase, a well-structured pipeline can handle the added load without compromising performance. This allows your system to scale smoothly, adapting to growth without a hitch.
- Improved efficiency. Automating data flows within a pipeline frees up valuable resources, enabling your team to concentrate on analysis, strategic planning, and decision-making. This leads to enhanced operational efficiency and better outcomes overall.
Example of Data Pipeline Architecture Diagram
A pipeline architecture is like a roadmap guiding your information from its raw beginnings to the point where it fuels insightful decisions. Let’s learn how to build a data pipeline:
- Data sources. Picture this as the starting line of your journey. Whether you’re pulling from databases, tapping into APIs, or capturing information streams, this is where everything kicks off.
- Data ingestion. This is where the real work begins—collecting all that information. Tools like Apache Kafka or AWS Kinesis are like the unsung heroes, quietly gathering insights from various sources and prepping it for the next stage.
- Data processing. Now comes the transformation. At this stage, data pipeline tools like Apache Spark or AWS Glue take over, cleaning, transforming, and enriching the information to become useful and insightful.
- Data storage. Once insights are ready, they need a place to live. This is where storage solutions such as lakes, warehouses, or databases come into play. Consider options such as Amazon S3, Google BigQuery, or Snowflake as the comfy homes where your data settles in.
- Data analysis. Here’s where the magic happens—turning information into insights. With the help of tools such as Tableau, Looker, or custom dashboards, you can dive into the data, analyze it, and uncover valuable insights to drive your decisions.
- Data access. Finally, it’s time to unlock the full potential of facts and figures. Users and applications can access the information through BI tools or APIs, making it an influential asset in your decision-making toolkit.
Let’s look at the his is how all these pieces fit together in a cohesive visual architecture:
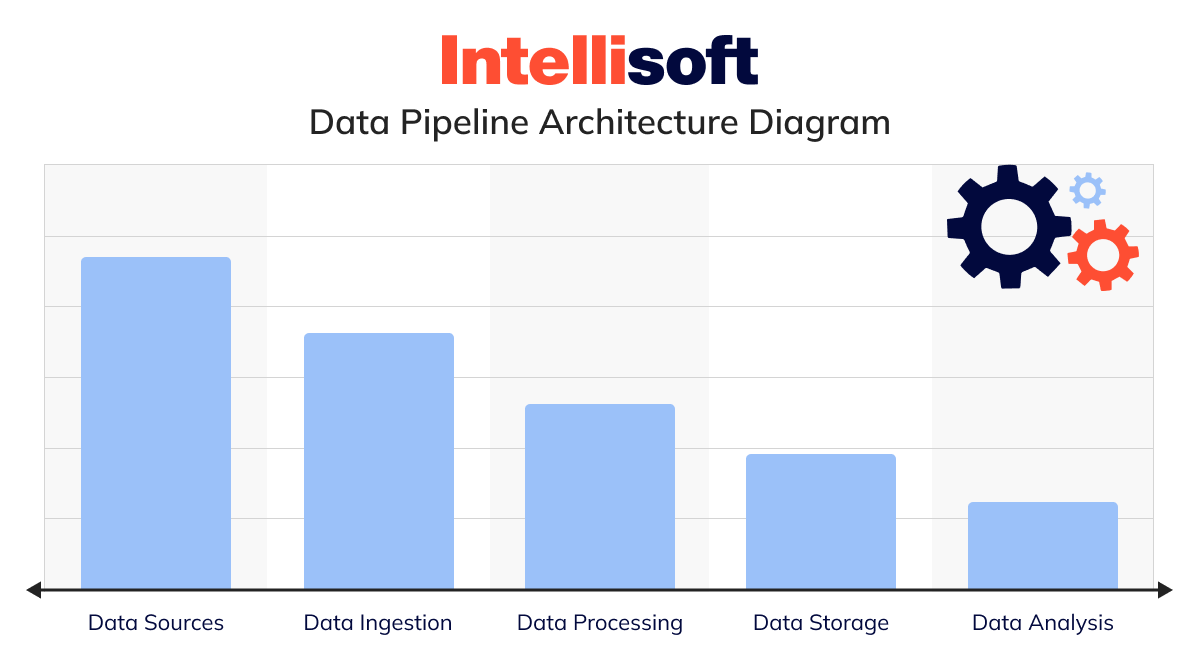
This data pipeline diagram offers a streamlined overview of how information flows through a pipeline, from its collection to the point of analysis.
ETL Data Pipeline
As mentioned earlier, ETL is the most widely used big data pipeline architecture, a standard that has endured for decades. It involves extracting raw insights from various sources, transforming it into a unified format, and loading it into a target system, typically an enterprise data warehouse or data mart.
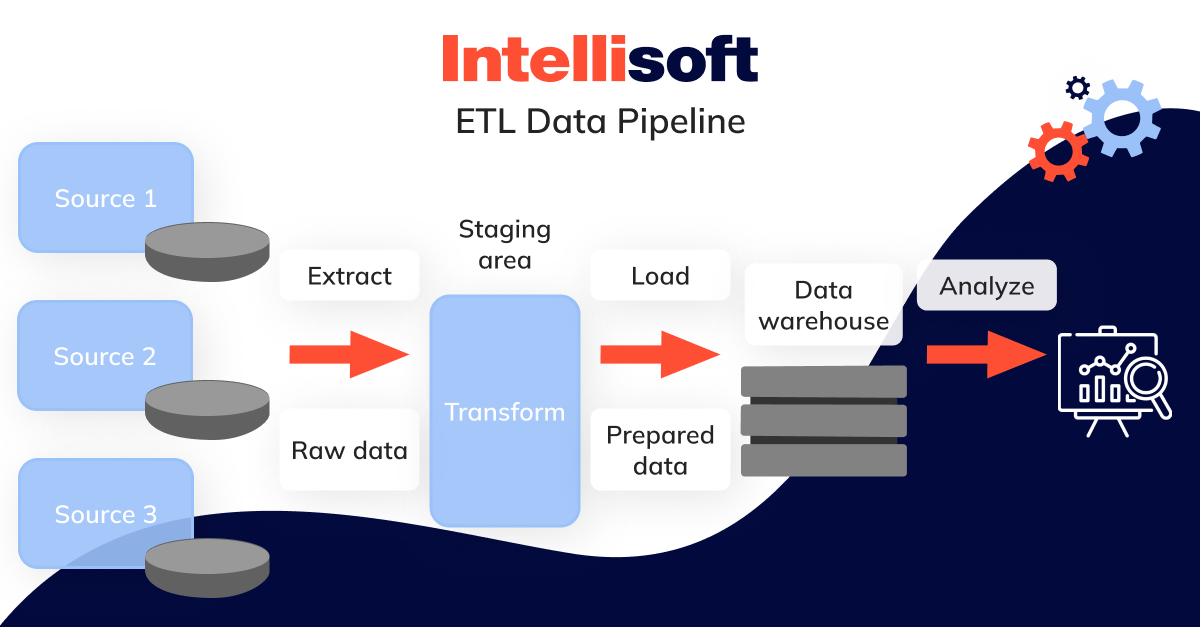
Data pipeline ETL Is commonly used in several scenarios:
- Migrating information from old legacy systems to a modern warehouse.
- Gathering user insights from various touchpoints to centralize customer information, typically in a CRM system.
- Bringing together large volumes of insights from diverse internal and external sources to create a comprehensive view of business operations.
- Combining different datasets to facilitate more in-depth analytics.
Nonetheless, a significant limitation of the ETL architecture is its rigidity; any changes to business rules or format requirements necessitate a complete rebuild of the data analysis pipeline. The ELT (Extract, Load, Transform) approach has emerged as a more flexible alternative to address this challenge.
Zero ETL
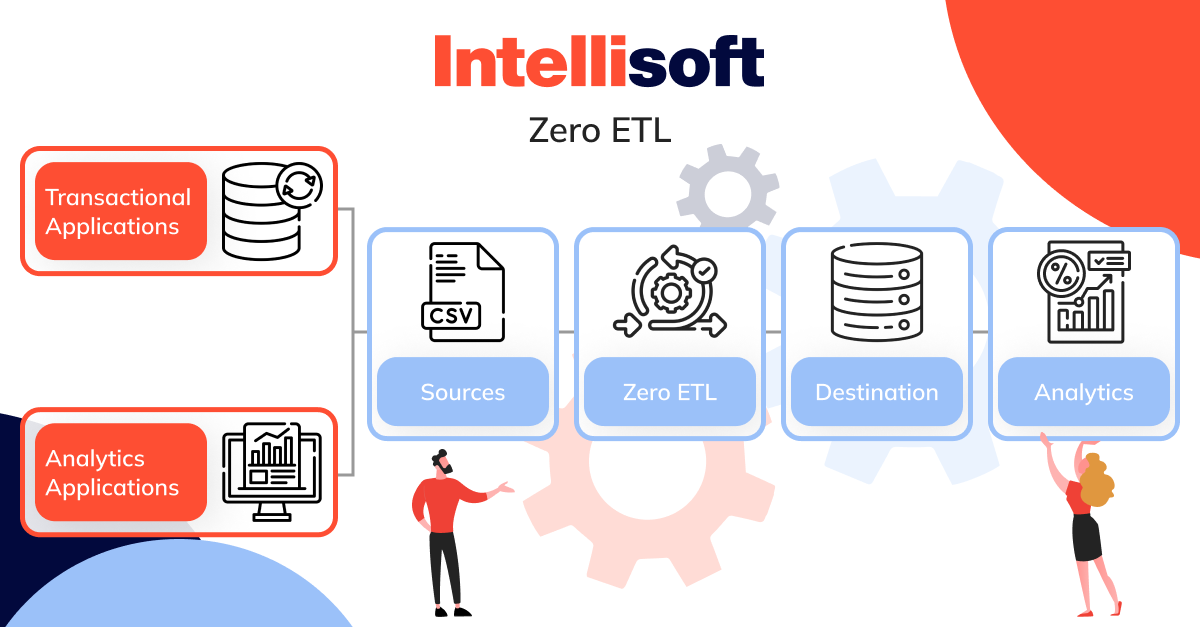
Traditional ETL processes often feel cumbersome—time-consuming, difficult to develop, and expensive to scale. However, with Zero ETL, information integration becomes far more straightforward. Rather than grappling with the usual steps of transforming or cleaning information, Zero ETL allows for smooth, direct transfer from one point to another. This approach significantly reduces or eliminates the need for complex ETL pipelines, paving the way for real-time or near-real-time integration.
Zero ETL architectures perform best when your transactional database and warehouse are housed on the same cloud platform.
ELT Data Pipeline
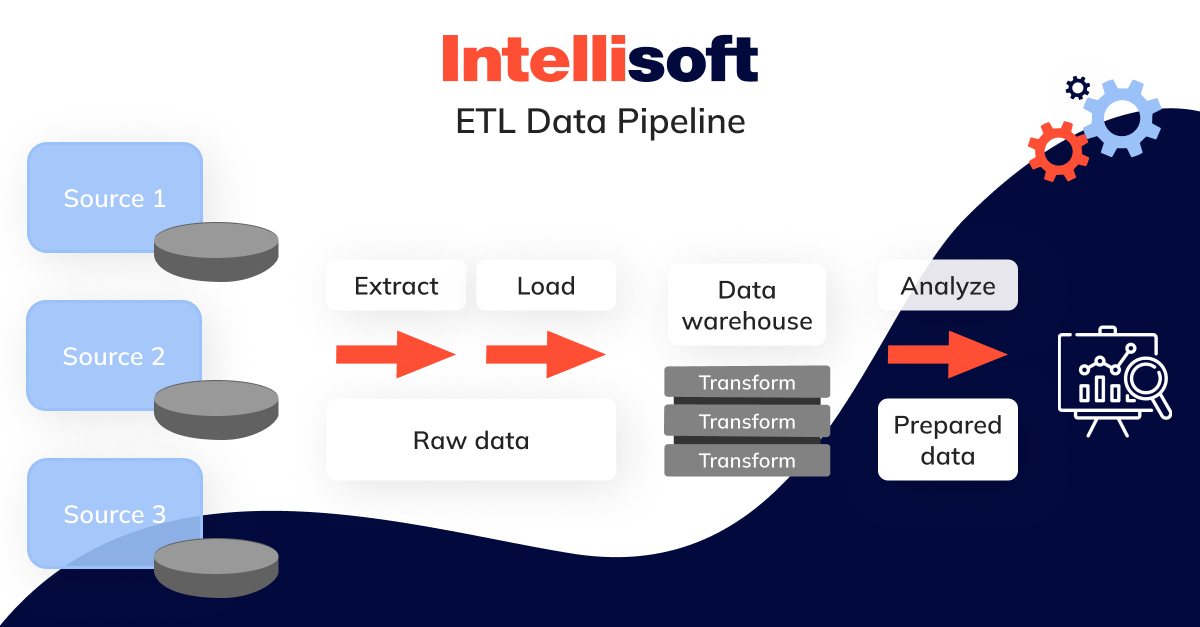
Think of ELT as turning the usual information processing method on its head. Unlike ETL, where you transform information before loading it, ELT rearranges the process—and this slight change has a significant impact. Instead of spending time and effort converting vast amounts of raw insights upfront, you load it directly into a data warehouse or data lake. From there, you gain the flexibility to process and organize your information whenever it suits your needs, whether all at once or in manageable data pipeline stages, as often as necessary. This approach offers you greater control and efficiency in managing your information.
ELT architecture is advantageous when:
- You’re unsure about how you’ll process your insights
- Rapid ingestion is critical
- Dealing with vast amounts of information.
However, despite these advantages, ELT is still less mature than ETL, leading to challenges regarding tool availability and the talent pool.
You can build your data pipeline using ETL, ELT, or a combination of both for traditional or real-time analytics.
Batch Pipeline for Traditional Analytics
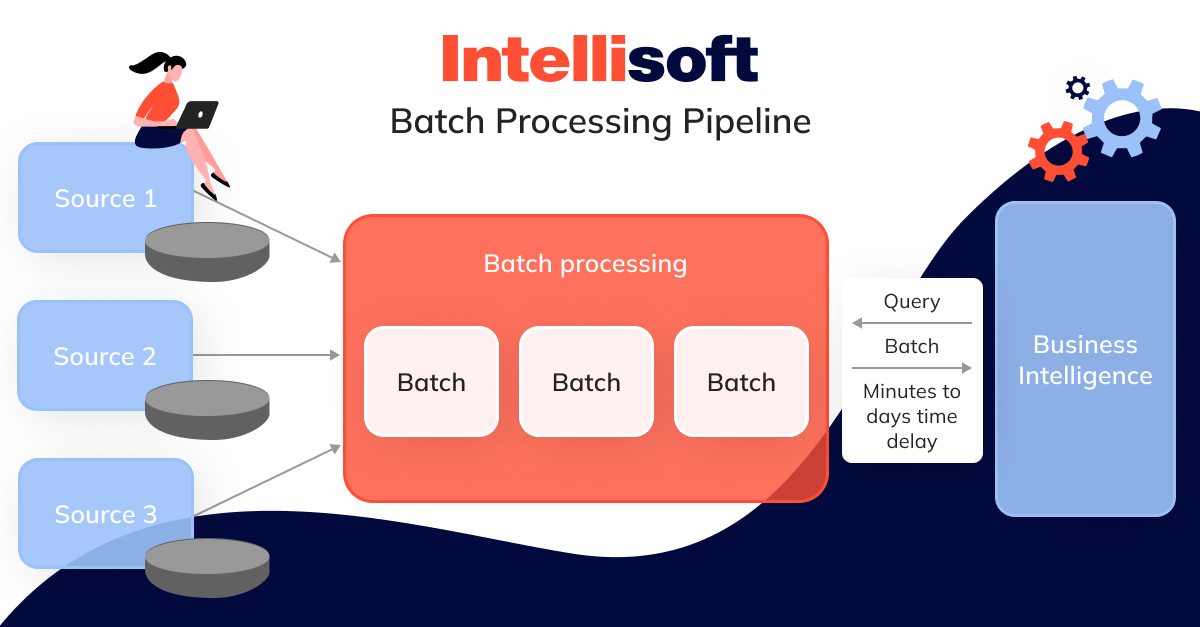
Traditional analytics focuses on interpreting historical information to support decision-making processes. It typically involves using business intelligence tools along with batch pipelines. This approach gathers, processes, and stores insights in large segments according to a set schedule. Once the information is ready, it can be queried for further exploration and visualization.
Based on the size, batch processing times can fluctuate significantly, ranging from just a few minutes to several hours—or even days. To prevent source systems from becoming overwhelmed, these processes are typically scheduled during off-peak times, such as late at night or over the weekend.
Though batch processing is a dependable method for managing large datasets in projects where timing isn’t critical, it falls short when you need real-time insights. For real-time information, opting for architectures designed for streaming analytics is more effective, as they deliver immediate results as information is received.
Streaming Data Pipeline for Real-time Analytics
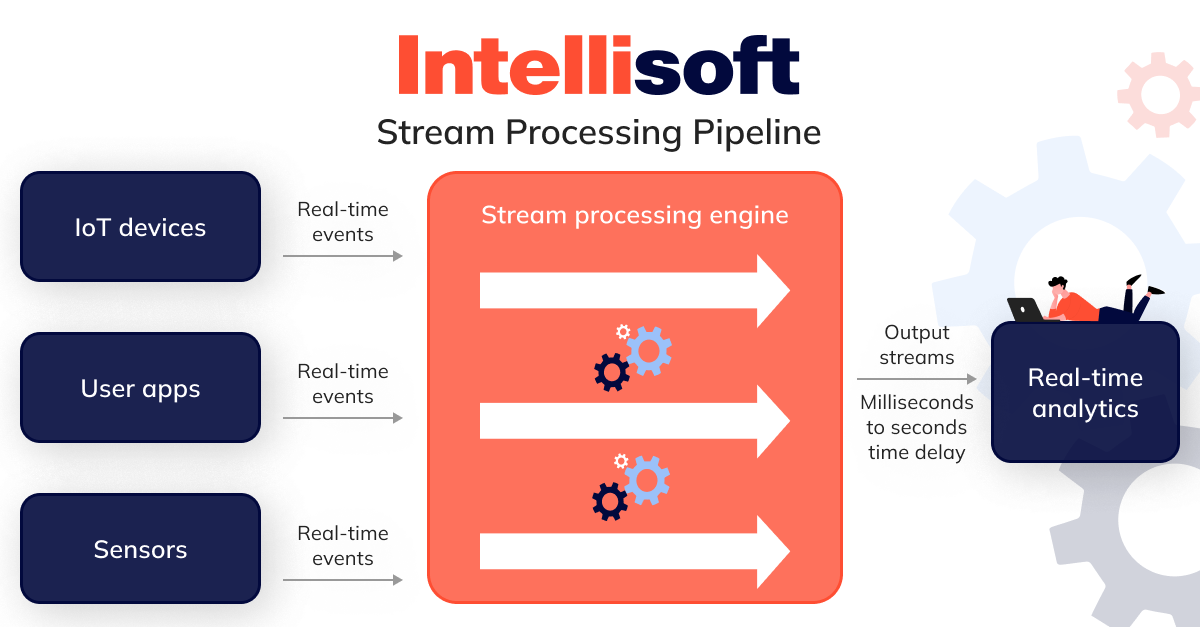
Real-time or streaming analytics lets you extract insights from continuous streams almost instantaneously. Unlike the traditional batch processing approach, which analyzes information in segments, streaming analytics works with information as it comes in, continuously updating metrics, reports, and statistics on the fly. This approach ensures you’re continually operating with the most current letters and figures, allowing for quicker decision-making and more agile responses.
Real-time analytics offers companies the advantage of accessing up-to-the-minute information about their operations, enabling them to react instantly and address issues without delay. This is particularly crucial for data pipeline solutions designed to monitor infrastructure performance intelligently. For businesses where any lag in information processing could be detrimental — such as fleet management companies using telematics systems — opting for a streaming architecture over batch processing is essential.
Big Data Pipeline for Big Data Analytics
Such pipelines perform the same core tasks as their smaller counterparts, but what sets them apart is their ability to support Big Data analytics. This involves managing enormous volumes of insights from over a hundred sources, handling a wide range of formats, such as:
- Structured
- Unstructured
- Semi-structured
All these kinds of information process at high speeds. ELT is ideal for loading vast amounts of raw facts and figures and enabling real-time streaming analytics, extracting insights on the fly. However, thanks to modern data pipeline software, batch processing and ETL have also become capable of handling large-scale information.
Organizations typically use batch and real-time pipelines to analyze Big Data effectively, combine ETL and ELT processes, and employ multiple stores to manage different formats.
Related articles:
- Top 10 Data Warehouse Software Tools for Your Business
- How to Master an Enterprise Data Warehouse: a Complete Guide
- Predictive Analytics in Retail: Boosting ROI and Transforming Customer Experience
- Best Tech Stack for Optical Character Recognition Automation
- Best programming languages for AI and machine learning
Building a Data Pipeline: Common Data Pipeline Solutions
This is why considering these solutions’ roles within a modern pipeline is often more practical. Depending on their perspective, this is a 5- or 7-layer stack, as illustrated in the image below.
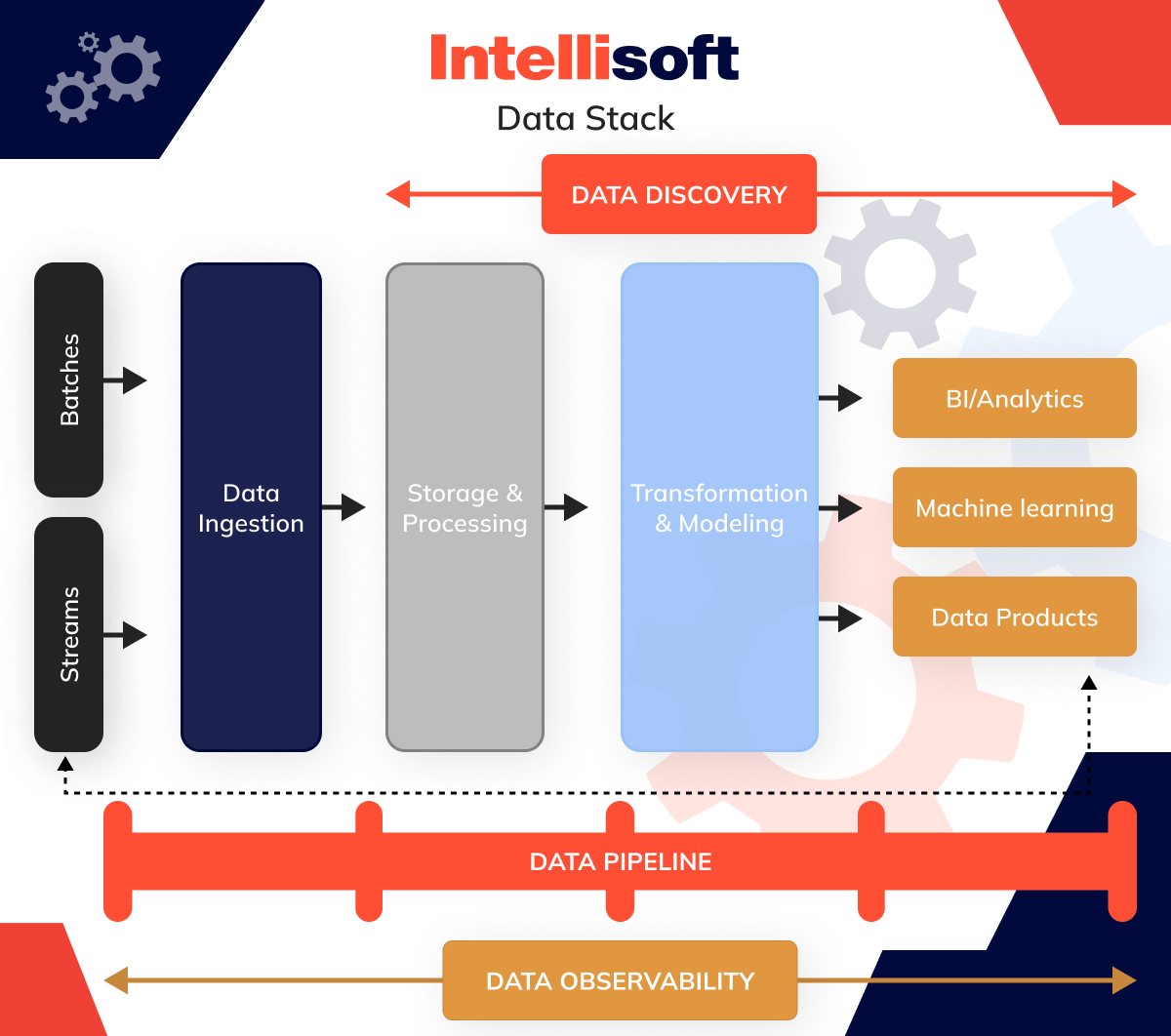
Data Storage and Processing
Your SQL queries aren’t just an afterthought—they’re the backbone of your data engineering pipeline architecture. When information flows from one table or frame to another in your system, those queries are essential to maintaining insights quality and optimizing performance. Even the most minor tweaks can make a significant difference.
Look at some of the most popular cloud warehouse options available.
- Snowflake. Snowflake data pipeline stands out for its flexible payment model—you only pay for what you use. It separates costs for computing and storage, giving you more control over your expenses.
- Google BigQuery. Thanks to parallel processing, Google’s BigQuery is a serverless solution known for its lightning-fast queries. Like Snowflake, it separates storage and compute, making it scalable and efficient.
- Amazon Redshift. A top choice for many, Amazon Redshift is tightly integrated with data pipeline AWS, making it an excellent option if you’re already using Amazon’s ecosystem.
- Firebolt. This cloud warehouse is all about speed, boasting performance up to 182 times faster than its competitors through advanced compression and parsing.
- Microsoft Azure. If your team is heavily invested in Windows, Microsoft Azure’s cloud solution is a natural fit, offering robust computing power and seamless integration.
- Amazon S3. More than just a storage solution, Amazon S3 supports structured and unstructured information, making it ideal for building a comprehensive data lake from scratch.
- Databricks. This solution combines the strengths of data lakes and warehouses, providing cost-effective storage for all types of information.
- Dremio. Dremio’s engine provides a self-service platform that empowers analysts, scientists, and engineers to work effortlessly with data lakes.
Data Ingestion
Two solutions are applicable here: batch ingestion and stream ingestion. When it comes to batch data ingestion pipeline, there are several standout solutions to consider:
Fivetran
This enterprise-grade ETL tool simplifies the delivery process, ensuring that information moves seamlessly from its source to the final destination without the usual headaches.
Singer
Singer is an open-source option That makes it easy to move insight between various sources and destinations, offering flexibility and simplicity.
Stitch
Stitch is a cloud-based, open-source platform that enables information to transfer quickly and effortlessly from one point to another.
Airbyte
Another open-source platform, Airbyte, is built for straightforward data syncing from various applications, making it a versatile choice.
If you need to deal with data ingestion pipeline architecture, here are some key players:
Apache Kafka
Backed by Confluent, Kafka is a leading open-source platform for managing real-time streams and analytics. Confluent’s integration with Apache Flink further enhances its capabilities, pushing the boundaries of what’s possible in streaming solutions.
Amazon Kinesis
Kinesis is tailored for AWS environments and provides a smooth streaming experience. It is particularly well-suited for Redshift warehouses, making it an ideal choice for AWS users.
Google Pub/Sub
This powerful service, offered by Google Cloud Platform, allows seamless information to stream into BigQuery, data lakes, or operational databases. Google’s latest update lets you bypass traditional pipelines and stream directly into BigQuery, significantly simplifying the ingestion.
Apache Spark
Widely recognized as a unified analytics engine, Spark data pipeline processes large-scale information. It’s particularly effective for streaming applications, especially when paired with Databricks, making it a go-to solution for many.
Data Orchestration
Airflow is widely regarded as the go-to orchestrator among analytics teams. Consider it a smart, automated scheduler that handles your workflows. It ensures that each task within your workflow happens in the correct sequence and at the precise time, making the whole process seamless and efficient.
Besides Airflow, other popular data pipeline orchestration tools include Prefect, Dagster, and Mage.
Data Transformation
In most cases, development teams use the following tools:
- dbt. dbt is an open-source game changer that transforms how we handle information. Once your letters and figures are loaded into the warehouse, you can effortlessly shape and refine it, ensuring it’s primed for analysis.
- Dataform. Now part of Google Cloud, this data pipeline tool helps convert raw information in your warehouse into actionable insights. The critical link between raw insights and the BI tools brings your information to life.
- SQL Server Integration Services (SSIS). Developed by Microsoft, it is a reliable choice for extracting, transforming, and loading information from various sources to your preferred destination. It provides precise control over your flow.
In the past, engineers often relied on pure Python code and Apache Airflow for data transformations. While custom code offers great flexibility, it can also be prone to errors and inefficiencies, requiring rewrites for each new process. Modern tools like dbt have streamlined these tasks, making transformation simpler and more dependable.
Business Intelligence and Analytics
Looking for the ideal BI tool? Here’s a quick look at some top options:
Looker
Designed for big data, Looker makes it easy for your team to collaborate on creating insightful reports and dynamic dashboards. It’s built to manage complex tasks, making your information work feel effortless.
Sigma Computing
If you enjoy the simplicity of spreadsheets but need the power of cloud-scale analytics, Sigma is the perfect fit. With familiar visualizations, it’s like a supercharged spreadsheet.
Tableau
As a leader in the BI space, Tableau stands out for its intuitive interface, making visualization simple for everyone, from beginners to experts.
Mode
This solution combines SQL, R, Python, and visual analytics into one easy-to-use platform, allowing your specialists to work together seamlessly.
Power BI
Power BI integrates seamlessly with Excel from Microsoft, making self-service analytics accessible to your whole team. It’s the tool that simplifies data-driven decisions for everyone, regardless of expertise.
Data Observability
Monte Carlo is a data pipeline observability tool revolutionizing how businesses handle information. By cutting downtime by up to 80% and increasing your engineers’ productivity by 30%, Monte Carlo moves away from outdated, manual testing. Instead, it leverages advanced machine learning models that detect and fix issues faster and prevent them from occurring in the first place. This approach keeps your insights flowing seamlessly and lets your team focus on what truly matters.
Data Catalog
Some organizations implement catalog solutions to enhance their governance and compliance efforts. These catalogs leverage metadata from modern platforms to offer detailed descriptions of essential assets such as tables, key metrics, and more—essentially serving as an ever-updating encyclopedia for your platform.
Below is a list of prominent catalog solutions that can be instrumental in managing pipelines:
- Alation. Delivers a comprehensive catalog featuring advanced search capabilities, robust data governance, and collaboration tools, helping organizations discover, comprehend, and manage their information effectively.
- Collibra. Provides a strong solution supporting data governance, stewardship, and metadata management. It seamlessly integrates with a variety of sources and tools.
- Google Cloud Data Catalog. A fully managed and scalable service designed to help users discover, manage, and govern information assets across the Google Cloud Platform.
- AWS Glue Data Catalog. Integrated with AWS Glue, this service offers a central repository for storing and managing metadata to facilitate processing and analysis processes.
- Azure Data Catalog. A cloud-based solution that aids users in discovering, understanding, and utilizing assets within Microsoft Azure and on-premises environments.
- Informatica Enterprise Data Catalog. Provides automated metadata management and discovery, enabling users to grasp data relationships and lineage more effectively.
- DataRobot. Incorporates a catalog feature within its machine learning platform, enabling users to manage and understand their data assets more efficiently.
- Atlan. Features a collaborative workspace with integrated metadata management, governance, and data collaboration tools.
Access Management
Ensuring your information is accessible only to those who genuinely need it is crucial in today’s digital landscape. As the stakes for protecting sensitive and personally identifiable information (PII) continue to rise, robust access management solutions are vital to safeguarding letters and figures and steering clear of hefty penalties from stringent regulations such as GDPR or CCPA. Here’s a look at some top vendors of data pipeline management solutions:
- Immuta. It simplifies the intricacies of managing and enforcing data policies, allowing organizations to grant quicker access to insights without sacrificing security.
- BigID. This tool offers a modern, scalable platform that brings privacy, protection, and insight across all your information, no matter where it’s stored.
- Privacera. It facilitates data access, security, and policy management across various cloud data pipeline services through a unified interface, enhancing control and visibility.
- Okera. This solution excels in providing multiple enforcement patterns and platform-agnostic, policy-based access controls, ensuring consistent policy enforcement across all environments.
- SatoriCyber. It separates security, privacy, and access controls from the data layer, enabling analytics teams to operate more agilely.
Data Pipeline Architecture Best Practices
Let’s explore the best practices for building data science pipeline architecture.

Simplify and Safeguard Your Data Pipeline with an Automated Data Lineage Solution
Tracking dependencies manually in a complex information environment is simply unfeasible, and when documentation does exist, it often leaves much to be desired. Without a clear picture of these dependencies, your analytics team risks unintentionally introducing breaking changes or becoming overly cautious, hesitating to make any changes for fear of negative downstream effects.
Build Your Data Pipeline to Be Modular and Automated
Frequent updates are the norm, so it’s better to build data pipeline that is simple rather than one that’s perfect but requires a complete overhaul whenever source data changes. While open-source solutions might seem appealing due to their lower initial costs, it’s crucial to consider the hidden costs of maintenance. Delays in integrations can cause your team to spend more time managing the architecture than extracting value from the information.
Establish Clear Data Pipeline SLAs (Service Level Agreements)
Your pipeline’s architecture should align with the specific needs of your use case. Do your users require information refreshed every second, minute, hour, or day? This will guide your choice between stream, micro-batch, or batch ingestion. Additionally, consider the required level of information quality—is exactness crucial, or is directional accuracy sufficient? Establishing these expectations ensures everyone is held accountable.
Let the Data Guide Your Pipeline Architecture
A warehouse-based architecture is the most logical choice for most teams dealing with structured letters and figures for analytics. On the other hand, teams working with unstructured information for analytics might prefer a data lake.
Some may even need to create custom architectures, much like the experience of Netflix Studios’ Senior Data Engineer, Dao Mi, at Nauto, where they developed AI software for driver safety. As Dao Mi noted, “We primarily dealt with telemetry and video from dashcams, which required us to design our storage and infrastructure around how we could best process this information, often leading to the development of homegrown solutions because commercial options weren’t available.”
Focus on Creating Data Products
Emphasize creating products by adopting the Data-as-a-Product approach, a concept introduced by Zhamak Dehgani’s data mesh framework. It’s more than just a dataset; it’s a valuable asset, such as a crucial table or dashboard, that is discoverable, secure, governed, reliable, and interoperable.
Continuously Monitor and Optimize Costs
Inefficient and degrading queries can inflate costs and compromise information reliability. Take advantage of our tips for optimizing Snowflake costs and identifying these expensive queries.
Ensure Your Pipelines are Idempotent
When your pipelines are idempotent, meaning they produce the same result no matter how often they run, you can avoid issues like inconsistent or duplicate insights.
Final Thoughts
Pipelines are the backbone of efficient data management, ensuring that information flows smoothly from start to finish. This approach facilitates quick analysis and informed decision-making. This article discussed the various data pipeline architecture examples, each tailored to address specific business needs.
We’ve also covered the data pipeline definition and best practices for constructing reliable pipelines, which are crucial in maintaining your information’s accuracy, dependability, and readiness. Additionally, by examining real-world data pipeline examples, we’ve demonstrated how these practices are effectively applied in different scenarios, providing valuable insights into confidently overcoming a wide range of challenges.
If you need help building pipelines, contact IntelliSoft today to review your case!